
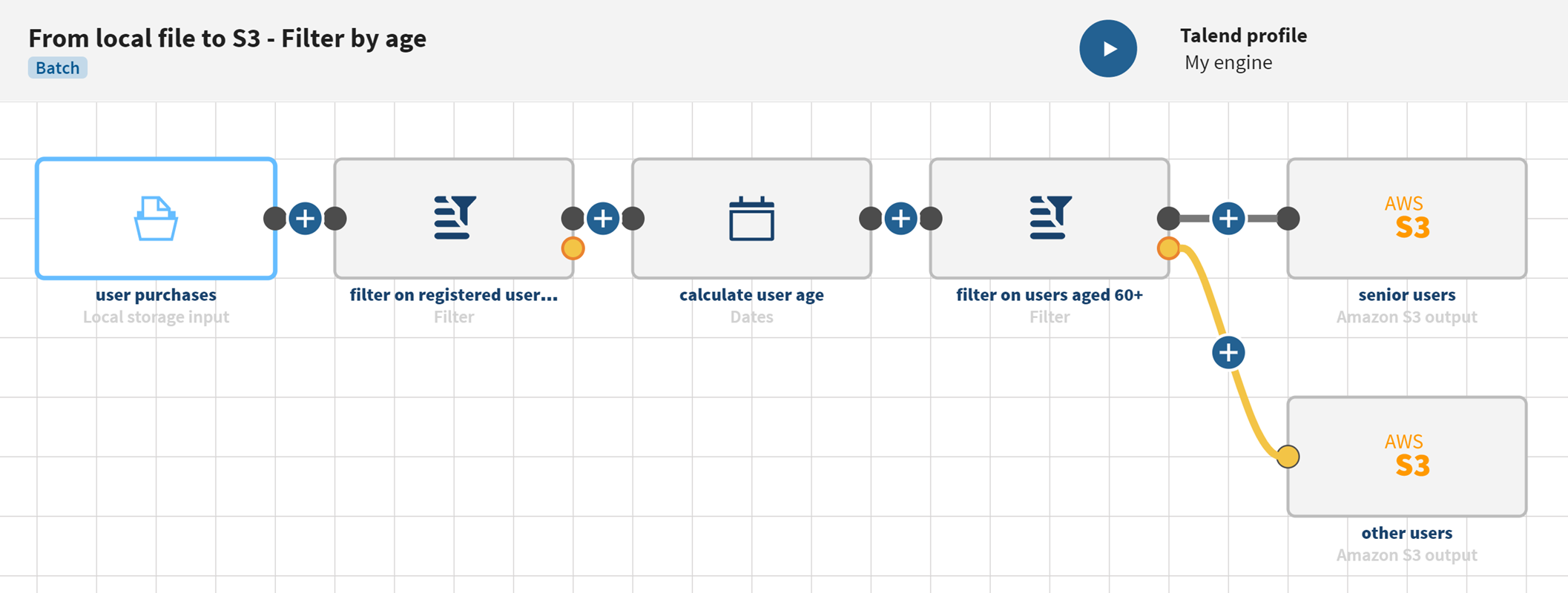
Filtering data from a local file and splitting it into two Amazon S3 outputs
This scenario aims at helping you set up and use connectors in a pipeline. You are advised to adapt it to your environment and use case.
Before you begin
- If you want to reproduce this scenario, download and extract the file: local_file-to_s3.zip . The file contains data about the user purchases with data about registration, purchase price, date of birth, etc.
Procedure
-
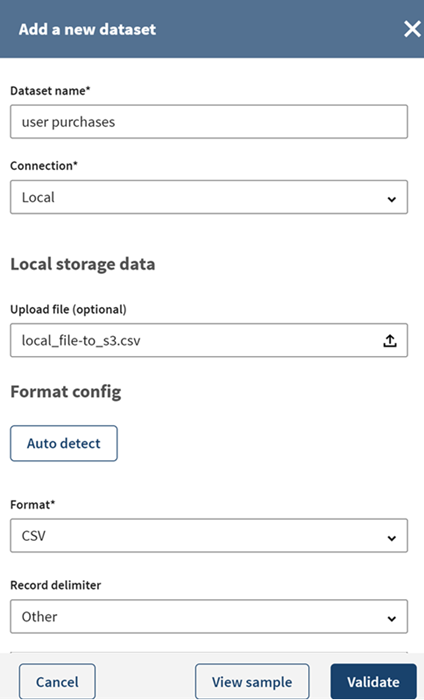
Click the
 icon to browse and select the local_file-to_s3.csv file
located on your machine, click Auto detect to automatically
fill the file format information then click View sample to see
a preview of your dataset sample.
icon to browse and select the local_file-to_s3.csv file
located on your machine, click Auto detect to automatically
fill the file format information then click View sample to see
a preview of your dataset sample.
-
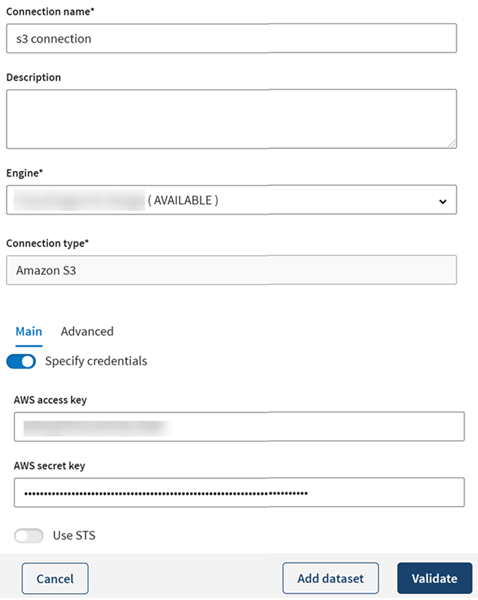
Do the same to add the Amazon S3 connection and S3 outputs
that will be used as Destinations in your pipeline. Fill in the connection
properties as described in Amazon S3 properties.
-
Click
 and add a Filter processor to the pipeline in order
to filter user data and give them a meaningful name. The configuration panel
opens.
and add a Filter processor to the pipeline in order
to filter user data and give them a meaningful name. The configuration panel
opens.
-
Click and add a Date processor to the pipeline in order to
calculate the age of users based on their date of birth. The configuration panel
opens.
-
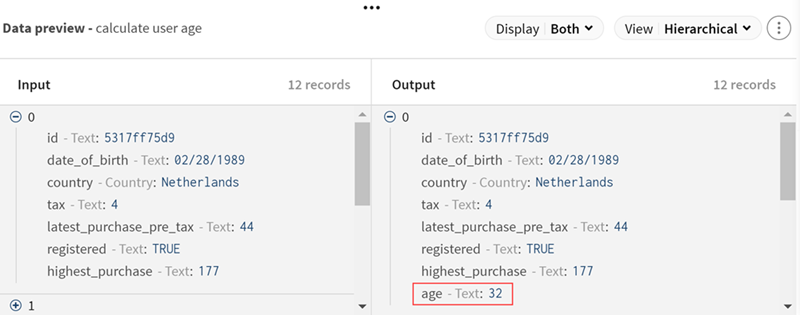
(Optional) Look at the preview of the processor to see the calculated
ages.
-
Click and add another Filter processor to the pipeline. The
configuration panel opens.
-
Click
 on the Filter processor to add another destination
and open the panel allowing to select the second dataset that will hold the output
data that does not match your filter (S3).
on the Filter processor to add another destination
and open the panel allowing to select the second dataset that will hold the output
data that does not match your filter (S3).
-
(Optional) Look at the Filter processor to preview the data after the filtering
operation: all registered users that are 60 years old or older.

Results
Your pipeline is being executed, the user information that was stored on your local file has been filtered, the user ages have been calculated and the output flows are sent to the S3 bucket you have defined. These different outputs can now be used for separate targeted marketing campaigns for example.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!