
Filtern von Daten zu Verbrechen in Google BigQuery-Tabellen
Dieses Szenario soll Sie bei der Einrichtung und Verwendung von Konnektoren in einer Pipeline unterstützen. Es wird empfohlen, dass Sie das Szenario an Ihre Umgebung und Ihren Anwendungsfall anpassen.
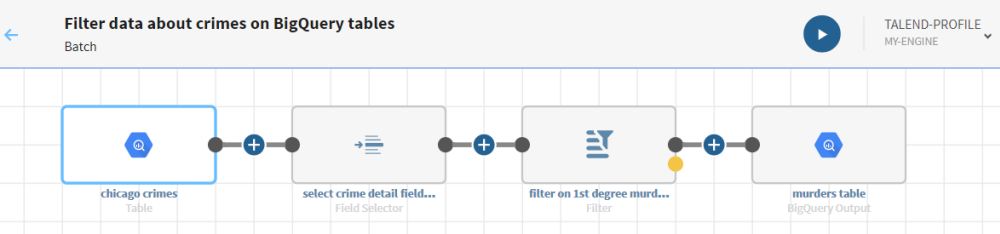
Vorbereitungen
-
Wenn Sie dieses Szenario nachvollziehen möchten, können Sie den offenen BigQuery-Datensatz chicago_crime (Verbrechen in Chicago) verwenden, der öffentlich zum Gebrauch zur Verfügung steht.
Prozedur
-
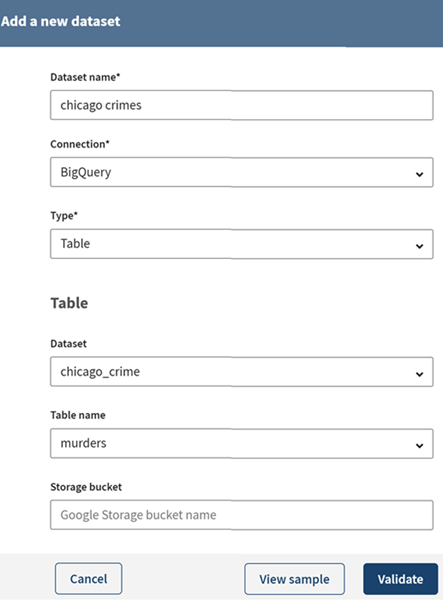
Geben Sie die erforderlichen Eigenschaften für den Zugriff auf die Datei in Ihrem BigQuery-Bucket ein (Datensatzname, Tabellenname oder Abfrage) und klicken Sie dann auf View sample (Sample anzeigen), um eine Vorschau Ihres Datensatz-Samples anzuzeigen.
-
Klicken Sie auf
 und fügen Sie einen Prozessor vom Typ Field selector (Feldauswahl) zur Pipeline hinzu. Daraufhin wird das Konfigurationsfenster geöffnet.
und fügen Sie einen Prozessor vom Typ Field selector (Feldauswahl) zur Pipeline hinzu. Daraufhin wird das Konfigurationsfenster geöffnet.
-
Klicken Sie auf und fügen Sie einen Filter-Prozessor zur Pipeline hinzu. Legen Sie einen aussagekräftigen Namen fest.
Example
filter on 1st degree murders (Morde ersten Grades ausfiltern) -
(Option) Sehen Sie sich die Vorschau des Filter-Prozessors an, um zu prüfen, wie Ihr Daten-Sample nach dem Filtervorgang aussieht.
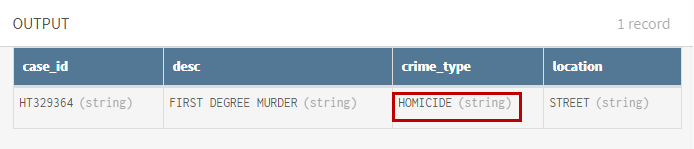
Ergebnisse
Ihre Pipeline wird ausgeführt, die Verbrechensdaten wurden verarbeitet und Tötungsdelikte isoliert und der Ausgabe-Flow wird an die von Ihnen angegebene Google BigQuery-Tabelle gesendet.
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!