
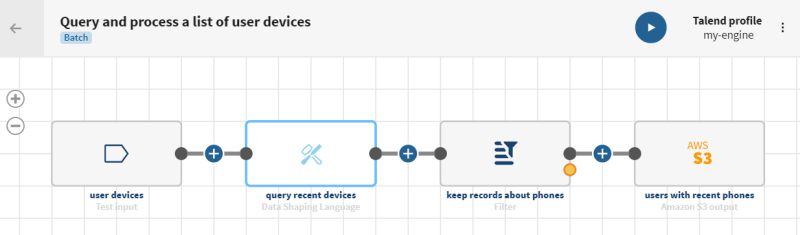
Verarbeiten einer Liste mit Benutzergeräten über Abfragen
Vorbereitungen
-
Sie haben zuvor eine Verbindung zu dem System erstellt, in dem die Quelldaten gespeichert sind.
In diesem Beispiel eine Testverbindung.
-
Sie haben zuvor den Datensatz hinzugefügt, der die Quelldaten enthält.
Laden Sie folgende Datei herunter und extrahieren Sie sie: query_language-devices.zip. Sie enthält eine hierarchische .json-Datei mit einer Umfrage zu Benutzergeräten, u. a. zu Gerätetyp, Kaufdatum, IP-Adressen usw.
-
Sie haben außerdem die Verbindung und den zugehörigen Datensatz erstellt, der die verarbeiteten Daten aufnehmen soll.
In diesem Beispiel eine in einem S3-Bucket gespeicherte Datei.
Prozedur
-
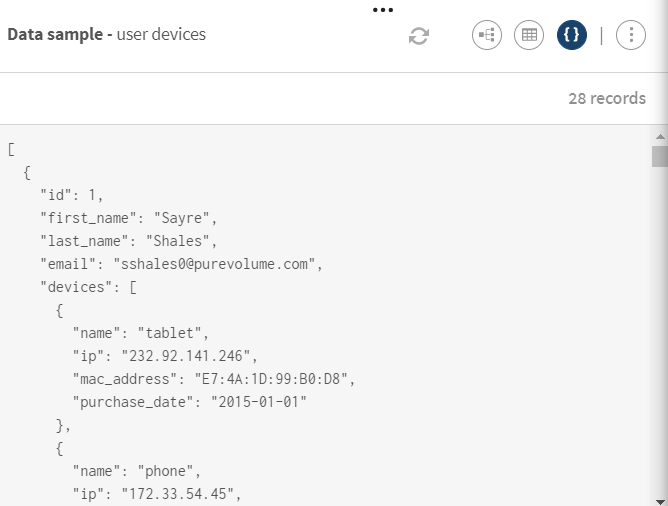
Klicken Sie auf ADD SOURCE (QUELLE HINZUFÜGEN), um ein Fenster zu öffnen, in dem Sie die Quelldaten, in diesem Fall eine Umfrage zu Benutzergeräten mit hierarchischen Daten, auswählen können.
Example
-
Klicken Sie auf
 und fügen Sie einen Prozessor vom Typ Data Shaping Language (Data-Shaping-Sprache) zur Pipeline hinzu. Das Konfigurationsfenster wird geöffnet.
und fügen Sie einen Prozessor vom Typ Data Shaping Language (Data-Shaping-Sprache) zur Pipeline hinzu. Das Konfigurationsfenster wird geöffnet.
-
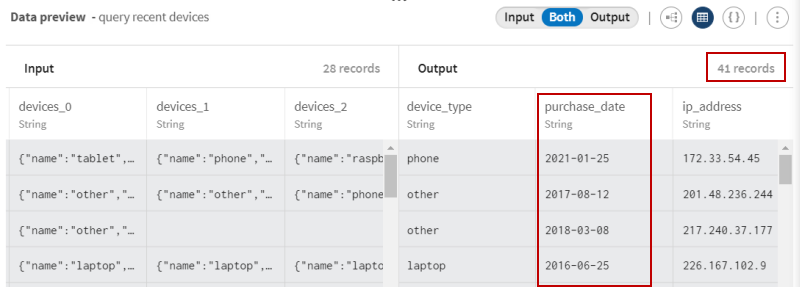
Klicken Sie auf Save (Speichern), um die Konfiguration zu speichern.
Die Vorschau ermöglicht die Visualisierung der neuen Struktur: Da die Struktur abgeflacht wurde, werden mehr Datenelemente ausgegeben und nur die nach dem 1. Januar 2015 gekauften Geräte angezeigt.
-
Klicken Sie auf und fügen Sie einen Prozessor vom Typ Filter zur Pipeline hinzu. Das Konfigurationsfenster wird geöffnet.
-
Führen Sie im Filterbereich Folgendes durch:
-
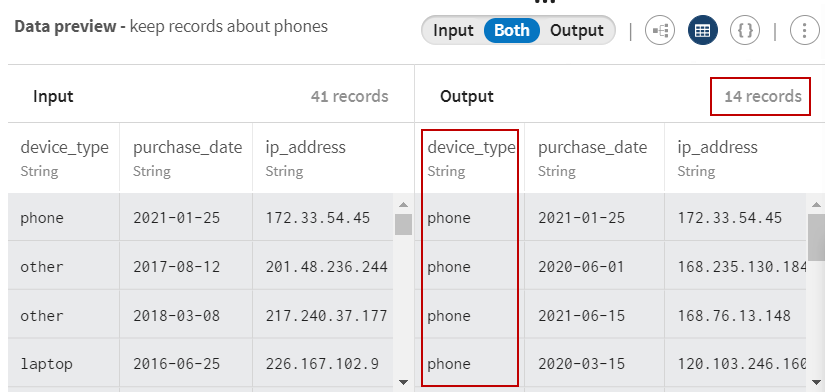
Klicken Sie auf Save (Speichern), um die Konfiguration zu speichern. In der Vorschau können Sie die Datensätze visualisieren, die den Filterkriterien entsprechen (Benutzer mit Telefonnummern).
-
Klicken Sie auf Save (Speichern), um die Konfiguration zu speichern. In der Vorschau können Sie die Datensätze visualisieren, die den Filterkriterien entsprechen (Benutzer mit Telefonnummern).
Ergebnisse
Die Pipeline wird ausgeführt, die Daten werden gemäß den von Ihnen mithilfe der Abfragesprache angegebenen Bedingungen gefiltert und die Ausgabe wird an das von Ihnen angegebene Zielsystem gesendet.
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!