
Big Data
|
Funktion |
Beschreibung |
Verfügbar in |
|---|---|---|
| Unterstützung für Azure Synapse Analytics mit Spark Universal 3.2.x und 3.3.x in Spark Batch-Jobs | Sie können Ihre Spark Batch-Jobs in Azure Synapse Analytics mit Spark Universal 3.2.x und 3.3.x jetzt im Synapse-Modus ausführen. Die entsprechende Konfiguration können Sie in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark Batch-Jobs vornehmen.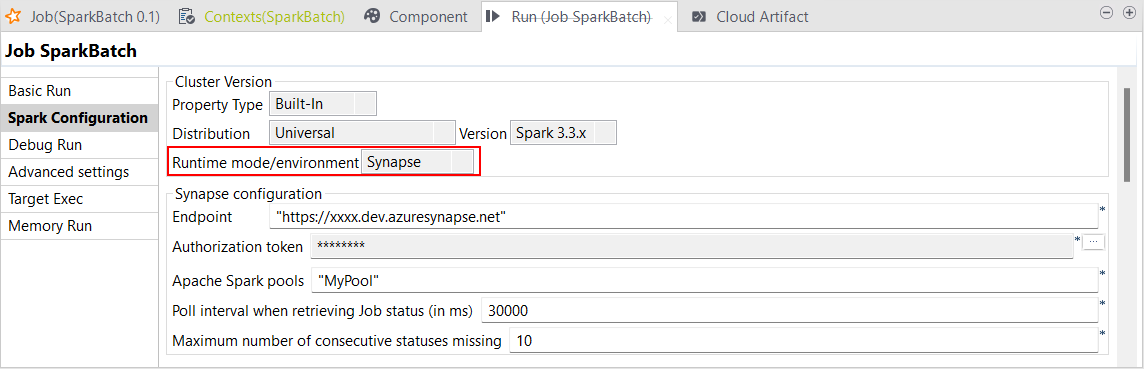
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für Elasticsearch 7.x und 8.x in Spark Batch-Jobs | Studio Talend unterstützt jetzt Elasticsearch 7.x und 8.x für die folgenden Komponenten in Spark Batch-Jobs:
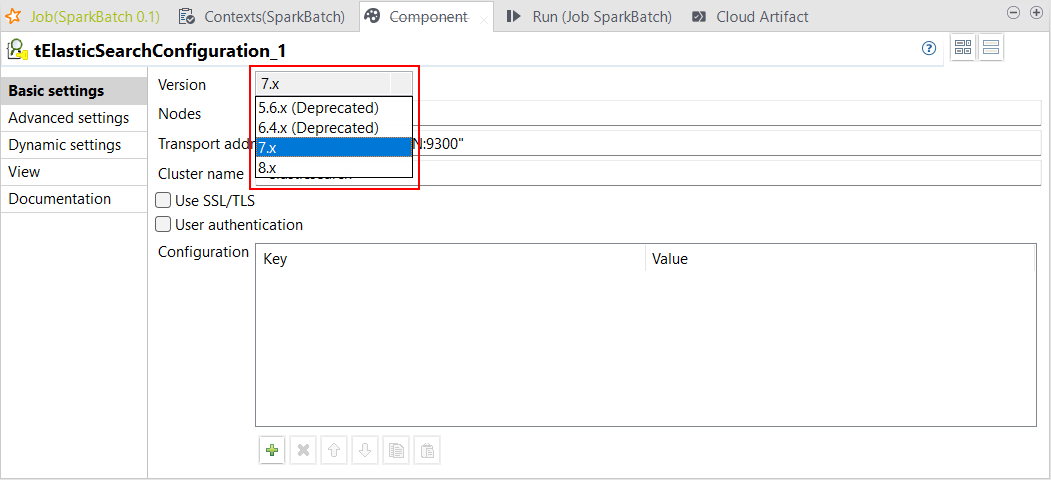
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für MongoDB v4+ für Spark Streaming ab Version 3.1 | Studio Talend bietet jetzt Unterstützung für MongoDB v4+ mit Spark ab Version 3.1 für die folgenden Komponenten in Spark Streaming-Jobs unter Verwendung von Dataset:
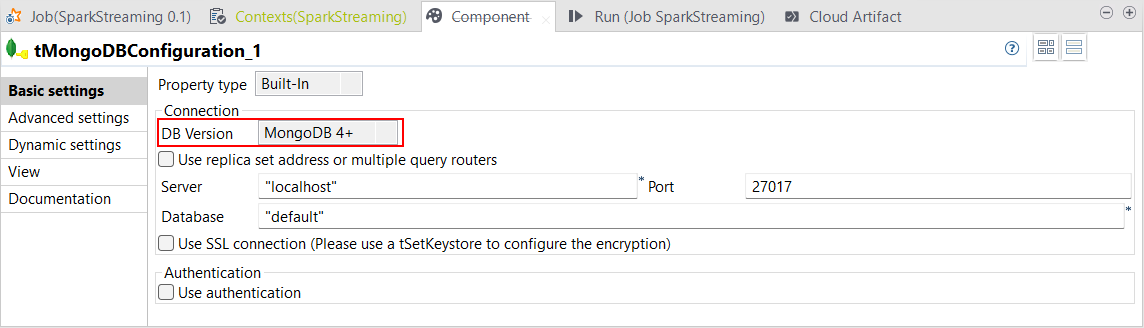
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für URI-Verbindungszeichenfolgen in tMongoDBConfiguration | Sie können in Ihren Spark Batch- und Streaming-Jobs jetzt eine Verbindung zu MongoDB über einen Uniform Resource Identifier (URI) definieren. Die Konfiguration erfolgt mithilfe des Parameters Use connection string (Verbindungszeichenfolge verwenden), der in tMongoDBConfiguration zur Verfügung steht. Damit können Sie spezifische Verbindungsparameter hinzufügen, wie z. B. das Präfix mongodb+srv, das für MongoDB Atlas in Spark Batch-Jobs verwendet wird. 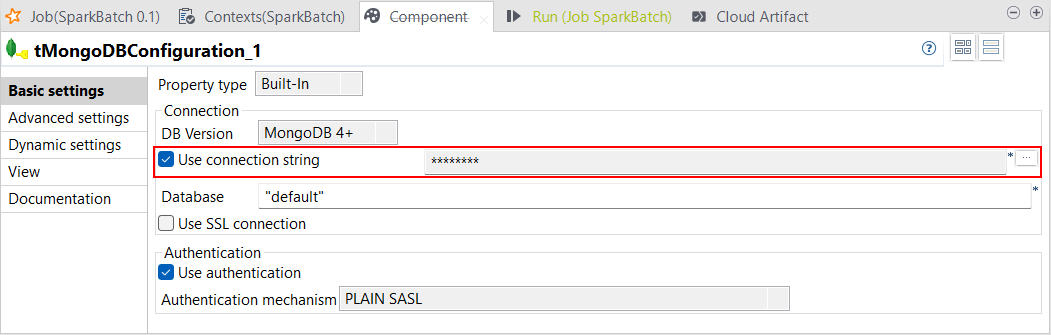
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!