
Big Data
|
機能 |
説明 |
対象製品 |
|---|---|---|
| Spark BachジョブでSpark Universal 3.2.xと3.3.xによるAzure Synapse Analyticsの使用をサポート | Spark Universal 3.2.xまたは3.3.xを使用するAzure Synapse Analyticsで、Spark BatchジョブをSynapseモードで実行できるようになりました。これはSpark Batchジョブの[Spark Configuration] (Spark設定)ビューで設定できます。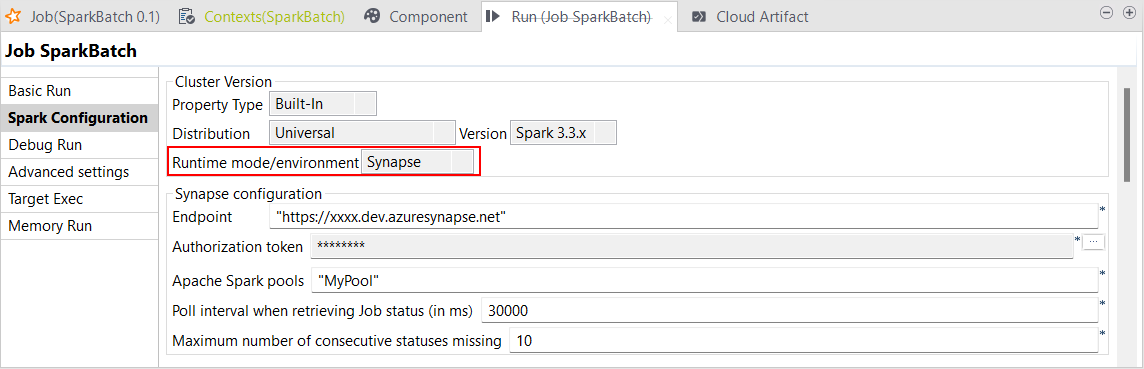
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| - Spark BatchジョブでElasticsearch 7.xと8.xをサポート | Spark Batch Jobsの次コンポーネントに関し、Studio TalendでElasticsearch 7.xと8.xがサポートされました。
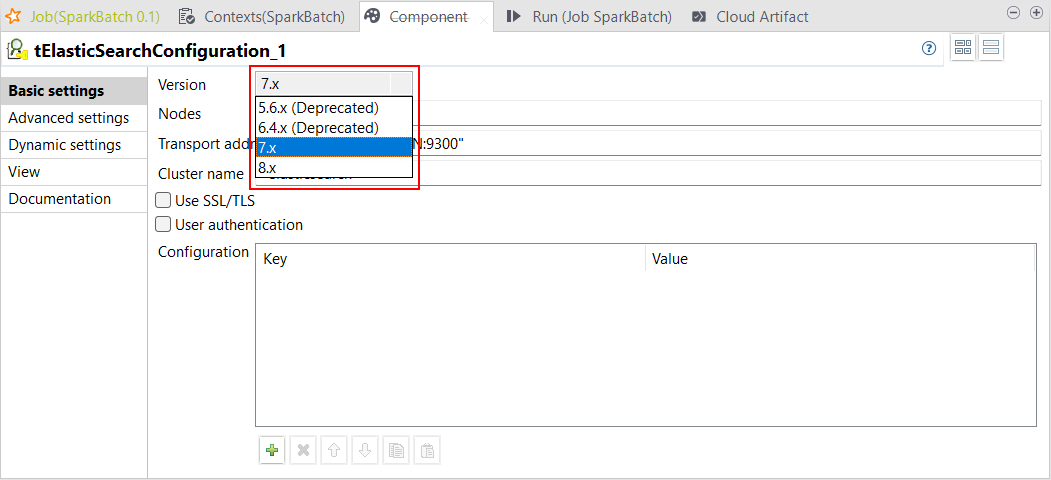
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| Spark Streaming 3.1以降でMongoDB v4+をサポート | データセットを使ったSpark Streamingジョブの次のコンポーネントに関し、Studio TalendでSpark 3.1以降のバージョンを使用するMongoDB v4+がサポートされました。
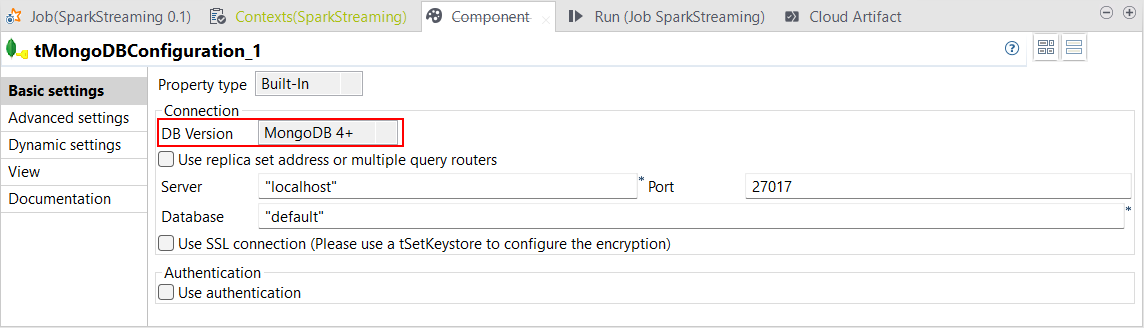
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| tMongoDBConfigurationでURI接続文字列をサポート | Spark BatchジョブとSpark Streamingジョブで、Uniform Resource Identifier (URI)を使ってMongoDBへの接続を定義できるようになりました。 この接続は、tMongoDBConfigurationにある[Use connection string] (接続文字列を使用)パラメーターを使って設定できます。これによって、Spark BatchジョブのMongoDB Atlasで使用するmongodb+srvプレフィックスなど、特定の接続パラメーターを追加できるようになります。 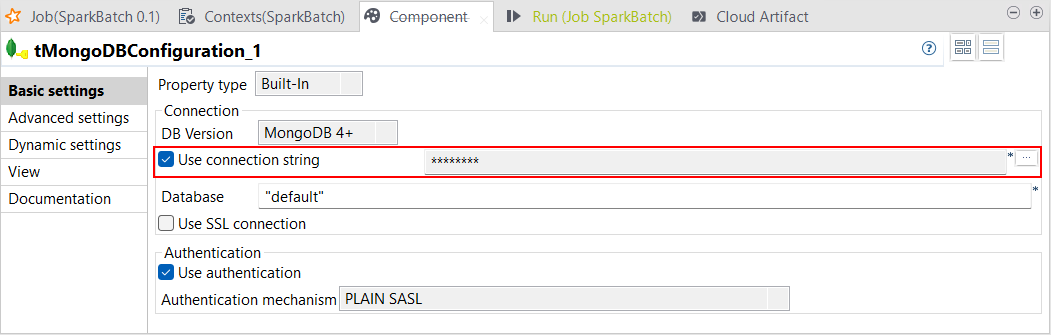
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。