Double-click tMahoutClustering to open
its Component view.
From the Schema list, select Built-In and then click the [...] button next to Edit
Schema and describe the data structure in the input
file.
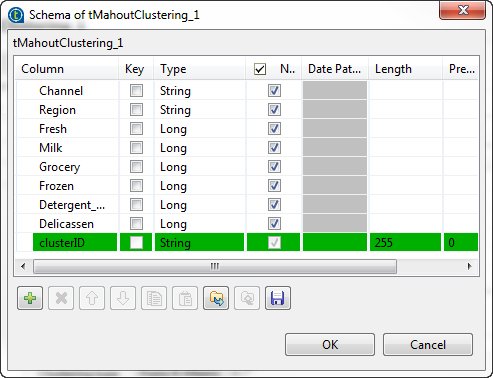
Add eight rows to the schema dialog box and define the input data as shown
in the above capture.
The component has one read-only column,
clusterID.
Click OK.
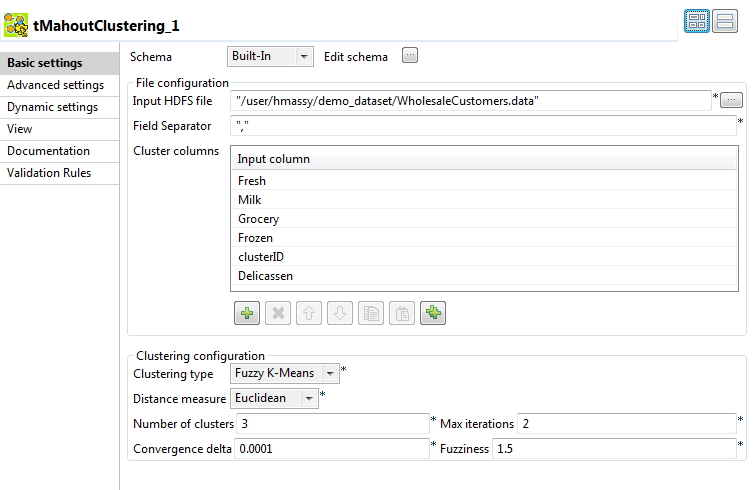
In the File Configuration area:
Click the [...] button next to
the Input HDFS file and browse to
the HDFS file on the Hadoop system that holds the input numerical
data you want to cluster.
Set the field separator used to separate the columns in the
clustered data.
In the Cluster columns table, add
rows to the table and click in each row to select a column from the
input schema.
In the Clustering Configuration
area:
From the Clustering Type list,
select what algorithm you want to use to cluster the numerical data,
Fuzzy K-means in this
example.
From the Distance Measure list,
select the distance measure you want to use for clustering.
In the Number of clusters field,
enter 3.
Leave the values in Max
iterations and Convergence
delta as they are.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – please let us know!