Double-cliquez sur le tMahoutClustering pour ouvrir sa vue Component.
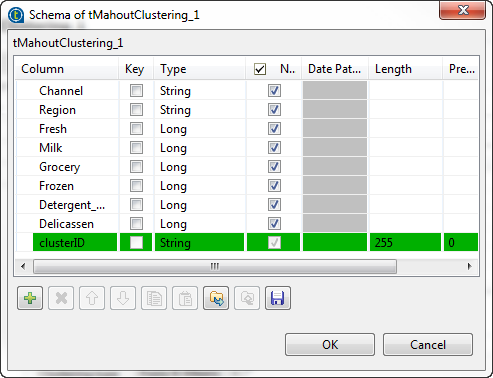
Dans la liste Schema, sélectionnez Built-In puis cliquez sur le bouton [...] à côté du champ Edit Schema et décrivez la structure des données dans le fichier d'entrée.
Ajoutez huit lignes au schéma et configurez les données d'entrée comme dans la capture d'écran.
Ce composant contient une colonne en lecture seule, clusterID.
Cliquez sur OK.
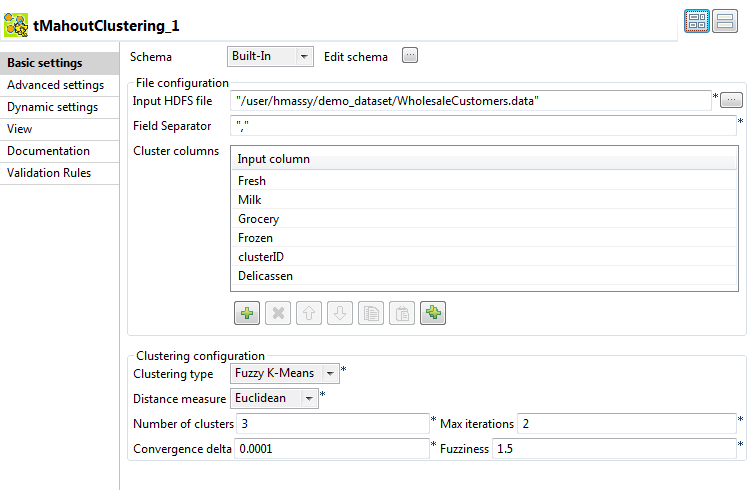
Dans la zone File Configuration :
Cliquez sur le bouton [...] à côté du champ Input HDFS file et parcourez votre système Hadoop jusqu'au fichier HDFS contenant les données numériques d'entrée que vous souhaitez mettre en clusters.
Configurez le séparateur de champs utilisé pour séparer les colonnes dans les données mises en clusters.
Dans la table Cluster columns, ajoutez des lignes à la table et cliquez dans chacune afin de sélectionner une colonne du schéma d'entrée.
Dans la zone Clustering Configuration :
Dans la liste Clustering Type, sélectionnez l'algorithme à utiliser pour mettre en clusters les données numériques, Fuzzy K-means dans cet exemple.
Dans la liste Distance Measure, sélectionnez la mesure de distance à utiliser pour le processus de clustering.
Dans le champ Number of clusters, saisissez 3.
Laissez les valeurs dans les champs Max iterations et Convergence delta telles qu'elles sont.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – faites-le-nous savoir.