
Writing Avro data to ProducerRecord
About this task
Configure the writing Job.
Procedure
-
From the writing Job, double-click the tFixedFlowInput
component to open its Basic settings view and specify the
following parameters:
-
Click the [+] button to add a column and give a
name to the column. For example:
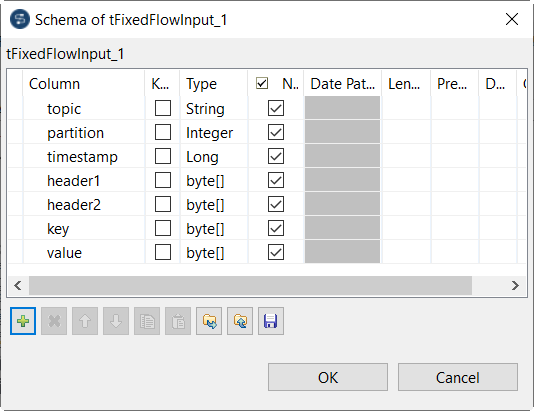
-
Click the [+] button to add a column and give a
name to the column. For example:
-
Double-click the tJavaRow component to open its
Basic settings view and specify the following
parameter:
-
Double-click the tKafkaOutput component to open its
Basic settings view and specify the following
parameters:
- From the Input type drop-down list, select ProducerRecord.
- From the Version drop-down list, select the version of the Kafka cluster to be used.
- In the Broker list field, enter the address of the broker nodes of the Kafka cluster to be used.
Results
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!