
Écrire des données Avro dans ProducerRecord
Pourquoi et quand exécuter cette tâche
Configurez le Job d'écriture.
Procédure
-
Depuis le Job d'écriture, double-cliquez sur le composant tFixedFlowInput pour ouvrir sa vue Basic settings et configurez les paramètres suivants :
-
Cliquez sur le bouton [+] pour ajouter une colonne et nommez cette colonne. Par exemple :
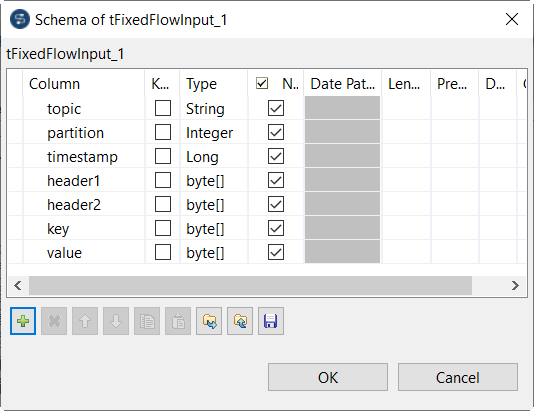
-
Cliquez sur le bouton [+] pour ajouter une colonne et nommez cette colonne. Par exemple :
-
Double-cliquez sur le tJavaRow pour ouvrir sa vue Basic settings et configurez le paramètre suivant :
-
Double-cliquez sur le tKafkaOutput pour ouvrir sa vue Basic settings et configurez les paramètres suivants :
- Dans la liste déroulante Input type, sélectionnez ProducerRecord.
- Dans la liste déroulante Version, sélectionnez la version du cluster Kafka à utiliser.
- Dans le champ Broker list, saisissez l'adresse des nœuds du broker du cluster Kafka à utiliser.
Résultats
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !