
Écrire des données dans un flux Amazon Kinesis
Avant de commencer
Dans cette section, supposez que vous avez un cluster Amazon EMR installé et en cours de fonctionnement et que vous avez créé la métadonnée de connexion correspondante dans le référentiel. Vous avez également créé un flux Amazon Kinesis.
Procédure
-
Créez un Job Big Data Streaming utilisant le framework Spark.
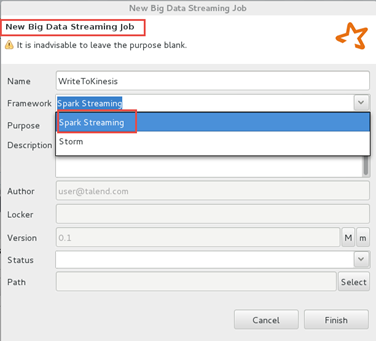
-
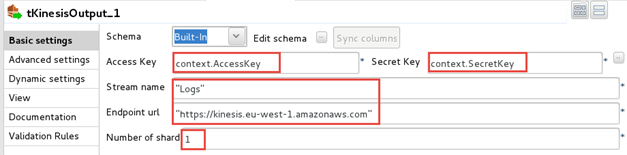
Saisissez le nombre de shards, comme spécifié lors de la création du flux Kinesis.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !