
Running the decision tree model using test data
This section explains how to test your decision tree model and examine how it predicts the target variable.
Procedure
-
In tFileInputDelimited, change the Folder/File value to point to the testing data.
The test data has the same schema as the training data. The only differences are the content details and the number of rows.
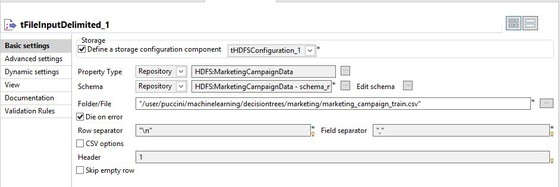
-
Add the path to the model you created in the previous section.
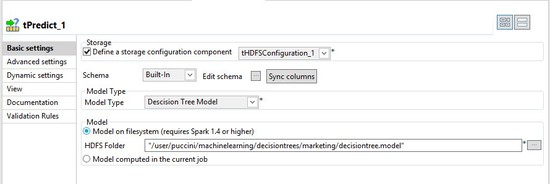
-
Click the Sync columns button, then click the
[...] button to edit the schema.
The output panel adds a new column named label. This is the placeholder for the predicted value produced by the decision model.
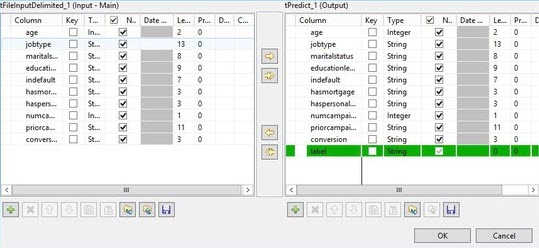
-
Add a tReplace to the workspace and connect
tPredict to it with a Main
row.
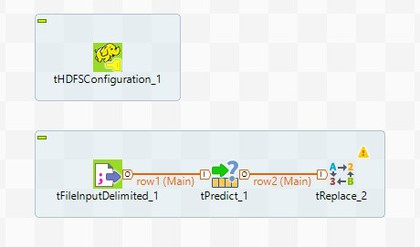
-
Configure tReplace as follows.
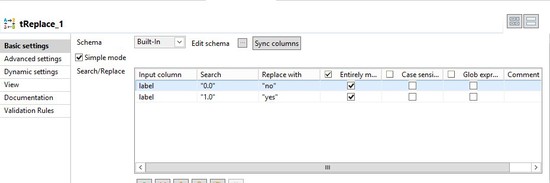
The tReplace is needed to convert the prediction output from tPredict from a boolean representation (0.0,10) to the representation of the testing data (yes/no).
-
Configure tAggregateRow as follows.
The Output column in the Operations section was chosen randomly. age was not chosen for any particular reason other than facilitating a count for the Group by.

-
Add a tLogRow to the workspace and connect
tAggregateRow to it with a Main
row.
Here is the Job configuration.

Results
The expected outcome of this Job is a tabular summary that demonstrates model prediction versus the actual true outcome.
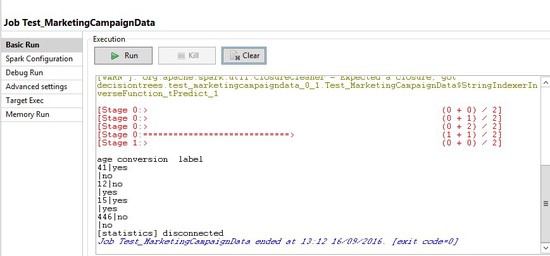
| count (age) | conversion (actual outcome) | label (predicted outcome) |
|---|---|---|
| 41 | yes | no |
| 12 | no | yes |
| 15 | yes | yes |
| 446 | no | no |
For a total of 514 test records, the output says the following:
- The model incorrectly predicted:
- (conversion = no) as true for 41 of the test cases
- (conversion = no) as false for 12 of the test cases
- The model accurately predicted:
- (conversion = no) as false for 15 of the test cases
- (conversion = no) as true for 446 of the test cases
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!