
Training the decision tree model
This section explains how to train your decision tree model.
Procedure
-
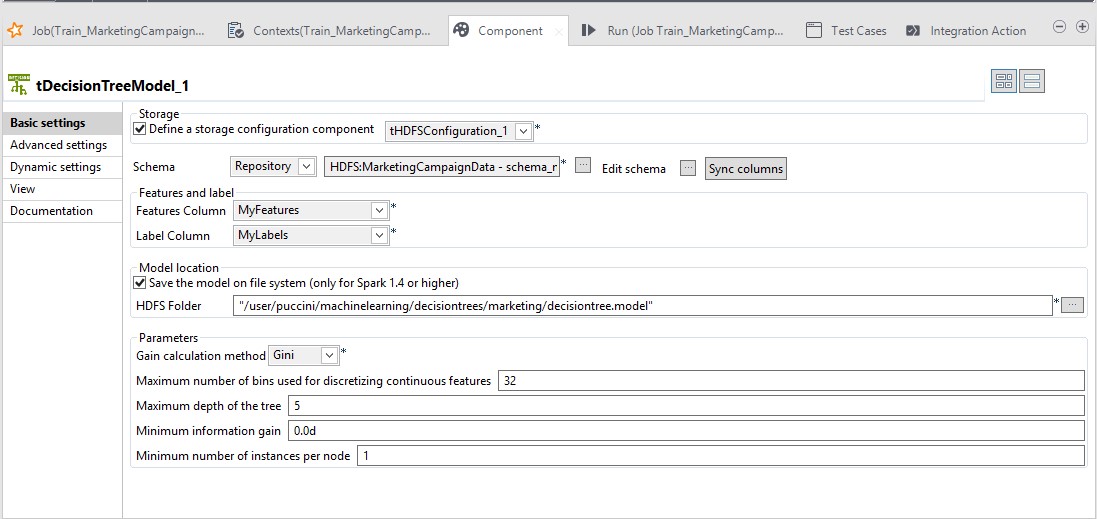
Leave the default value for the rest of the settings.
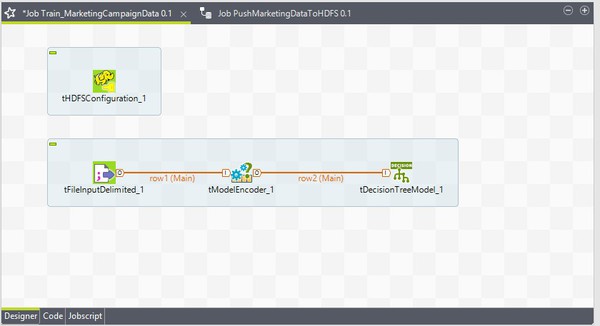
Here is the Job configuration.
-
Select the Use local mode check box.
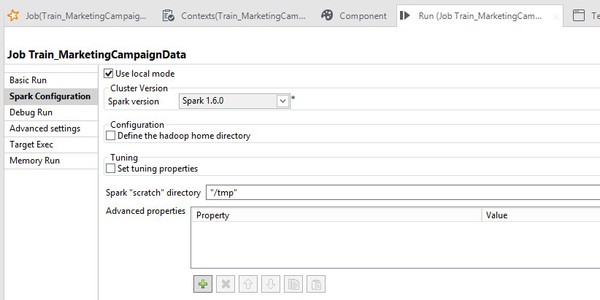 You can also run this Job directly on the Hadoop cluster, which is the most likely scenario in a production setting. For that, you need to make a few small adjustments to how the Job runs, including clearing the Use local mode check box.
You can also run this Job directly on the Hadoop cluster, which is the most likely scenario in a production setting. For that, you need to make a few small adjustments to how the Job runs, including clearing the Use local mode check box.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!