
Processing an Azure Synapse table and loading it into Azure Blob Storage
This scenario aims at helping you set up and use connectors in a pipeline. You are advised to adapt it to your environment and use case.
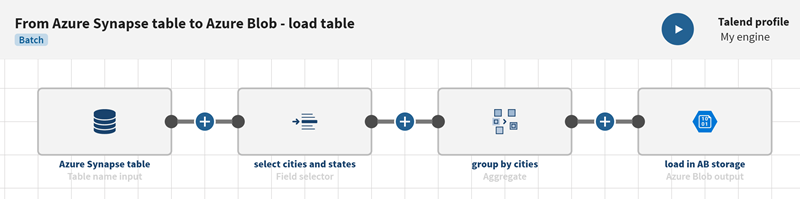
Procedure
-
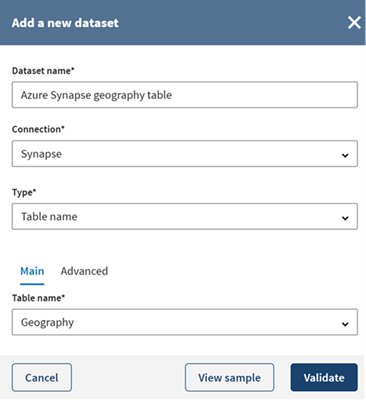
Fill in the required properties to access the table located in your database and
click View sample to see a preview of your dataset
sample.
-
Do the same to add the Azure Blob container that will be used as a destination in
your pipeline. Fill in the connection properties as described in Azure Blob Storage properties.
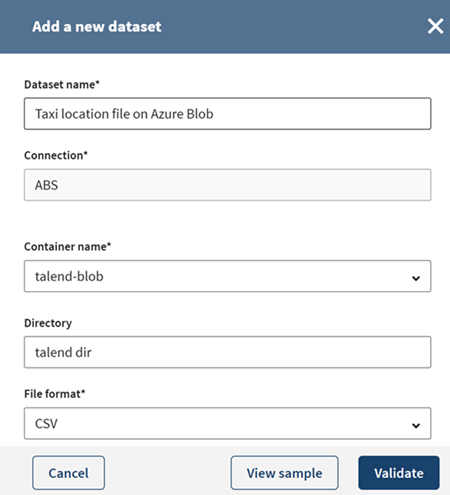 In this example, a CSV file containing data about taxi location located in the talend dir folder of an Azure Blob container called talend-blob will be used as the pipeline destination. You are able to see your container directories from the Storage Explorer page of your Azure Storage Account.
In this example, a CSV file containing data about taxi location located in the talend dir folder of an Azure Blob container called talend-blob will be used as the pipeline destination. You are able to see your container directories from the Storage Explorer page of your Azure Storage Account.
-
Click
 to add processors to the pipeline, for example a Field
selector to select specific fields and give them a meaningful name or
an Aggregate processor to list and group the records.
to add processors to the pipeline, for example a Field
selector to select specific fields and give them a meaningful name or
an Aggregate processor to list and group the records.
Results
Your pipeline is being executed, the taxi location information that was stored on Azure Synapse has been aggregated per cities and the output flow is sent to the Azure Blob target file you have defined.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!