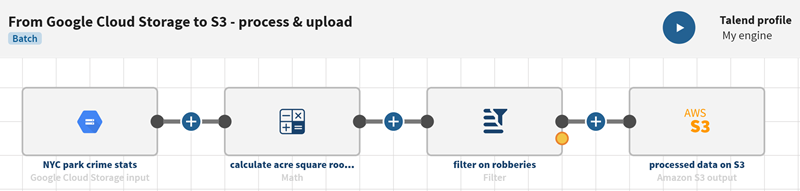
Processing statistics stored on Google Cloud Storage and uploading the data to Amazon S3
This scenario aims at helping you set up and use connectors in a pipeline. You are
advised to adapt it to your environment and use case.
Before you begin
If you want to reproduce this scenario, download the file: gcstorage_s3_nyc_stats.xlsx
.
This file is an extract of the nyc-park-crime-stats-q4-2019.xlsx
New York City open dataset that is publicly available for anyone to use.
Procedure
Click Connections > Add
connection.
In the panel that opens, select the type of connection you
want to create.
Example
Google Cloud
Storage
Select your engine
in the Engine list.
Information noteNote:
It is recommended to use the Remote Engine Gen2 rather than
the Cloud Engine for Design for advanced
processing of data.
If no Remote Engine Gen2 has been created from Talend Management Console or if it exists but appears as unavailable
which means it is not up and running, you will not be able to select
a Connection type in the list nor to
save the new connection.
The list of available connection types depends on the engine you
have selected.
Select the type of connection you want to create.
Here, select Google Cloud
Storage.
Fill in the JSON credentials needed to access your Google Cloud account as
described in Google Cloud Storage properties, check the
connection and click Add dataset.
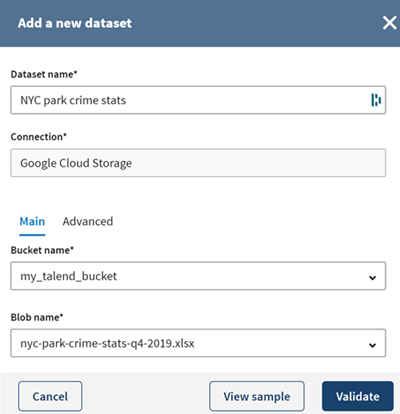
In the Add a new dataset
panel, name your dataset NYC park crime stats
crime.
Fill in the required properties to access the file located in your Google Cloud
Storage bucket (bucket name, file name, format, etc) and click View
sample to see a preview of your dataset sample.
Click Validate to save your dataset.
Do the same to add the S3 connection and dataset that will be used as a destination
in your pipeline.
Click Add
pipeline on the Pipelines page. Your new pipeline opens.
Click ADD SOURCE to
open the panel allowing you to select your source data, here a public dataset of
New York park crimes stored in a Google Cloud Storage bucket.
Select your dataset and click
Select in order to add it to the pipeline.
Rename it if needed.
Click and add a Math processor to the pipeline. The
configuration panel opens.
Give a meaningful name to the processor.
Example
calculate acre square
root
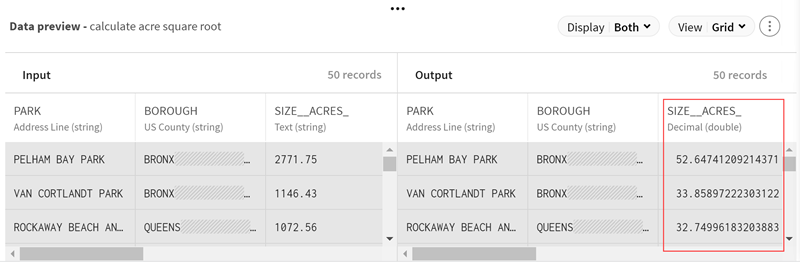
Configure the processor:
Select Square
root in the Function
name list, as you want to calculate the square root of
the SIZE__ACRES_ field.
Select .SIZE__ACRES_ in the Fields
to process list.
Click Save to
save your configuration.
(Optional) Look at the preview of the processor to see your data after the
calculation operation.
Click and add a Filter processor to the pipeline. The
configuration panel opens.
Give a meaningful name to the processor.
Example
filter on robberies
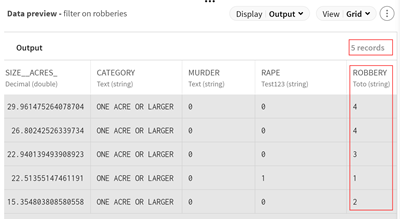
Configure the processor:
Add a new element and select .ROBBERY in the Input list, as you want to keep only
the robbery category among the crimes listed in the dataset.
Select None in the Optionally select a
function to apply list.
Select >= in
the Operator list.
Enter 1 in the
Value field, as you want to
filter on data that contains at least one robbery case.
Click Save to save your configuration.
(Optional) Look at the preview of the Filter processor to see your data sample after
the filtering operation.
Example
Click ADD DESTINATION
and select the S3 dataset that will hold your reorganized data.
Rename it if needed.
In the Configuration tab of the destination, enable the
Overwrite option in order to overwrite the existing file on
S3 with the file that will contain your processed data, then click
Save to save your configuration.
On the top toolbar of Talend Cloud Pipeline Designer,
click the Run button to open the panel allowing you to select
your run profile.
Select your run profile in the list (for more information, see Run profiles), then click Run to
run your pipeline.
Results
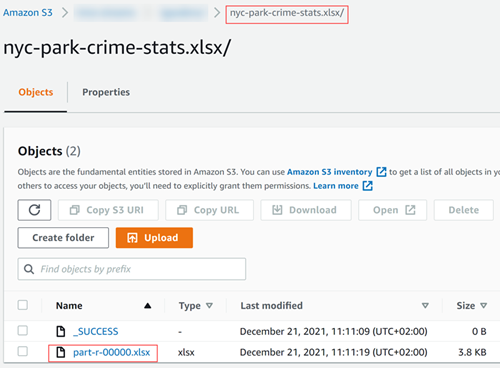
Your pipeline is being executed and the output flow is sent to the Amazon S3 bucket you
have indicated.
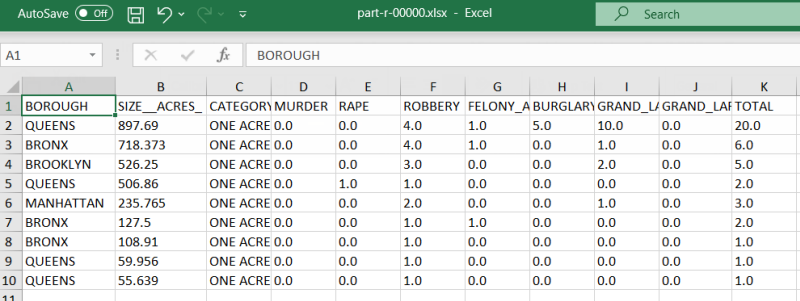
If you download the output file, you can see that the crime data has been processed and
robbery cases have been isolated.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!

 and add a Math processor to the pipeline. The
configuration panel opens.
and add a Math processor to the pipeline. The
configuration panel opens.