
About the Talend Trust Score™ with Snowflake
The native data quality compute in Snowflake is a tool that ensures the accuracy and reliability of your data.
It performs a comprehensive analysis of your dataset, and checks for validity and completeness. The data quality check is performed on the entire table in Snowflake.The validity check includes the data quality rules. For more information, see What is a data quality rule?.
From Talend Cloud Data Inventory, the Talend Trust Score™ evolution lets you track the quality of your datasets over time.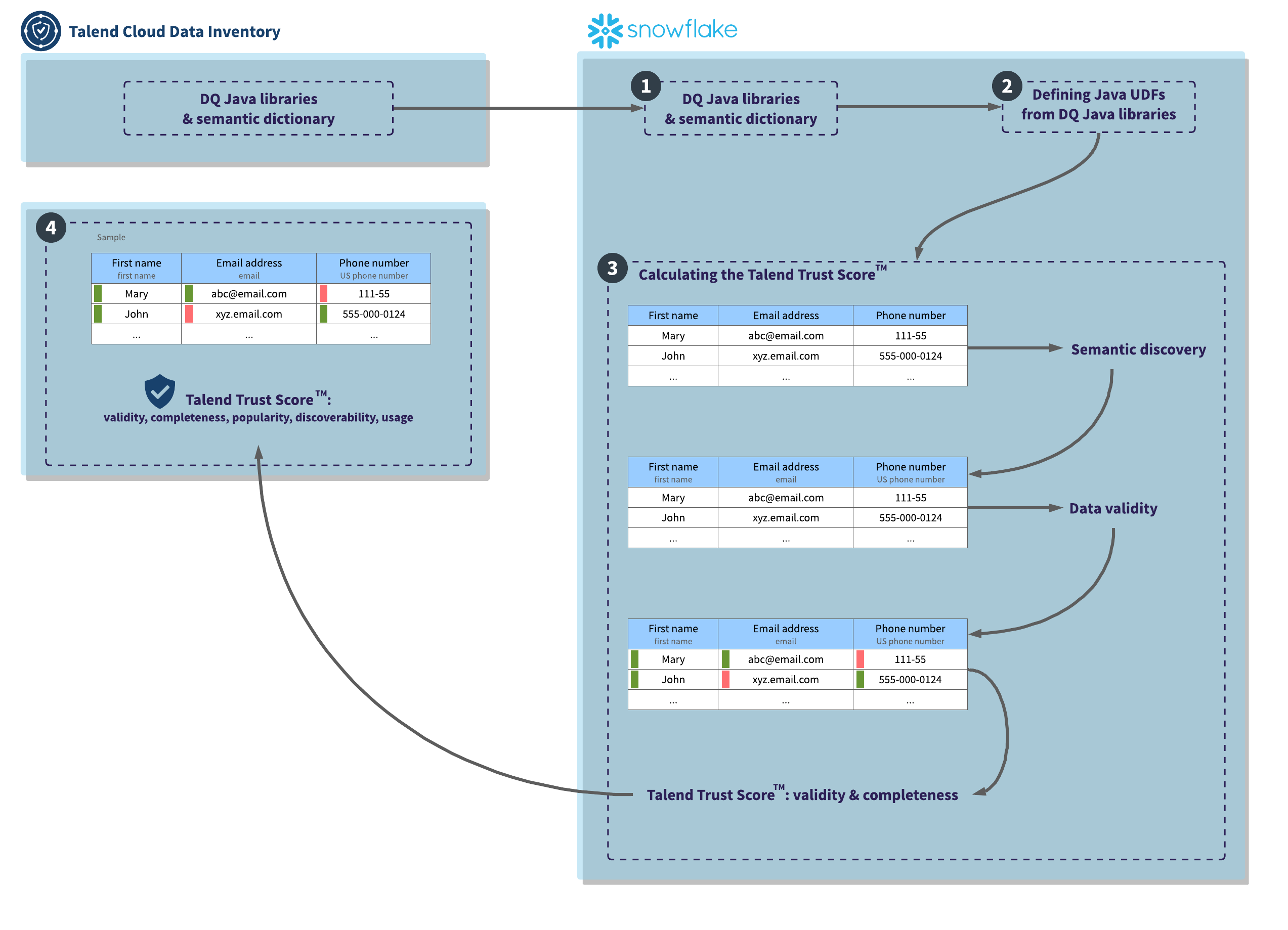
- Talend Cloud Data Inventory is compatible with Snowflake on AWS, GCP, and Microsoft Azure.
- You need some privileges to use Snowflake. See the Snowflake documentation.
- Using Snowflake with Talend Cloud Data Inventory impacts your Snowflake fees for computing.
- When you add a dataset from a Snowflake connection, a copy of the DQ Java libraries
and semantic dictionary is sent to Snowflake to perform the validity checks.Verify that the pushdown parameter is in the JDBC URL of the Snowflake connection. For example:For more information, see Adding the pushdown parameter to a Snowflake connection.
jdbc:snowflake://account.snowflakecomputing.com/?db=MY_DB&schema=PUBLIC&warehouse=MY_WAREHOUSE_WH&runProfile=sqlInformation noteTip: You can use the crawler to retrieve multiple tables and views. Using the Talend APIs, you can also automate the quality compute of . For more information, see Scheduling a crawler run. - The DQ Java libraries are defined as Java UDFs.
If you apply data quality rules to a dataset from Talend Cloud Data Inventory, they are also natively computed in Snowflake using the UDFs.
- To calculate the Talend Trust Score™ in
Snowflake, the following steps occur:
-
The semantic discovery defines the nature and the format of the data. The semantic type of each column of the dataset is checked by analyzing a sample of up to 10,000 rows. By default, the sample contains the first rows, called the Head sample. The rows can also be chosen randomly, called the Random sample.
- The data validity and completeness: the records are checked against the
semantic types to determine whether the fields are valid or invalid. If the
fields do not match a semantic type, they are checked against the native
types.
Using the JDBC URL from Talend Cloud Data Inventory, the validity and completeness are computed from the entire table in Snowflake.
From the dataset overview in Talend Cloud Data Inventory, you can preview a sample of the Snowflake table and retrieve valid and invalid records. This sample contains up to 10,000 records.
The data quality bars in the column and dataset headers represent the quality of the entire table.
-
Talend Trust Score™: the validity and completeness are calculated for the entire dataset in
Snowflake. You can find the history in Talend Cloud Data Inventory, as well as the Talend Trust Score™ evolution from the dataset overview.
You can also retrieve the Talend Trust Score™ from the dataset list and the data console.
-
- The sample is sent to Talend Cloud Data Inventory
and the Talend Trust Score™ of
the entire dataset is calculated as follows:
- The validity and completeness are natively computed in Snowflake on the entire table. The data quality rules compliance is also performed on the entire table.
- The popularity, discoverability, and usage are calculated in Talend Cloud Data Inventory. For more information on each axis, see Checking the Talend Trust Score™.
You now have the Talend Trust Score™ with five axes for your dataset.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!