
Big Data
|
Feature |
Description |
Available in |
|---|---|---|
| New component tManagePartitions to manage Spark datasets partitions in Spark Batch Jobs | A new component, tManagePartitions, is available in your Spark Batch Jobs,
replacing tPartition which is now deprecated. This component allows you to
manage your partitions by visually defining how an input dataset is
partitioned.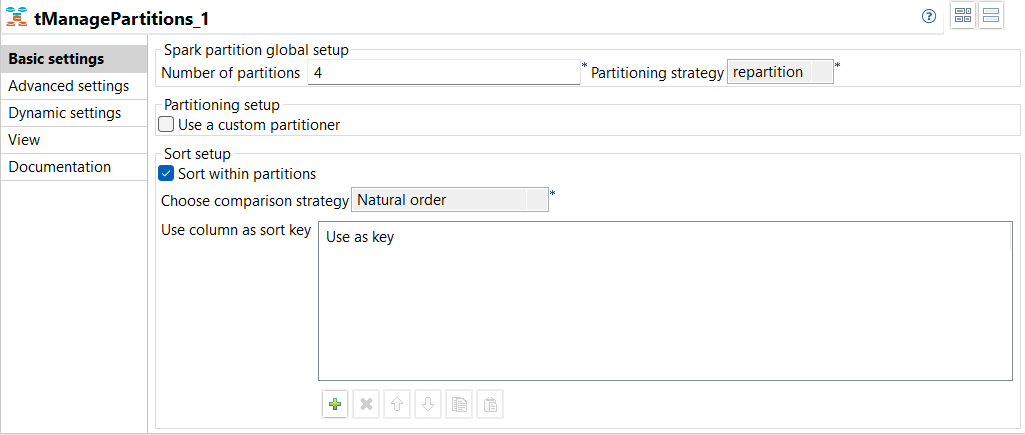
|
All subscription-based Talend products with Big Data |
| Support for auto partitioning with tManagePartitions in Spark Batch Jobs | A new option Auto is available in the
Partitioning strategy drop-down list from the
Basic settings view of tManagePartitions in your
Spark Jobs. This option allows you to calculate the best strategy to apply on a
dataset. 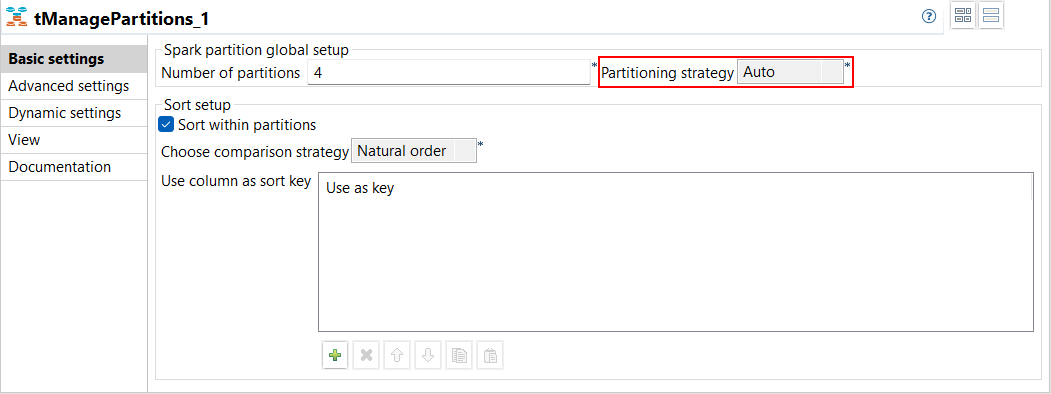
|
All subscription-based Talend products with Big Data |
| New component tCacheClear to clear Spark cache in Spark Batch Jobs | A new component, tCacheClear, is available in your Spark Batch Jobs. This
component allows you to remove the RDD (Resilient Distributed Datasets) cache
stored by tCacheOut from memory. Clearing the cache is a good practice, for example, if the caching layer becomes full, Spark will start evicting the data from memory using the LRU (least recently used) strategy. For this reason, unpersisting allows you to stay more in control about what should be evicted. Also, the more space you have in memory, the more it can be used by Spark for execution, for building hash maps for example |
All subscription-based Talend products with Big Data |
| Support for Kudu format with tImpalaCreateTable in Standard Jobs | The Kudu format is supported when creating a table with tImpalaCreateTable
in your Standard Jobs. When you work with a Kudu table, you can also configure
the number of partitions to be created with the new Kudu
partition parameter.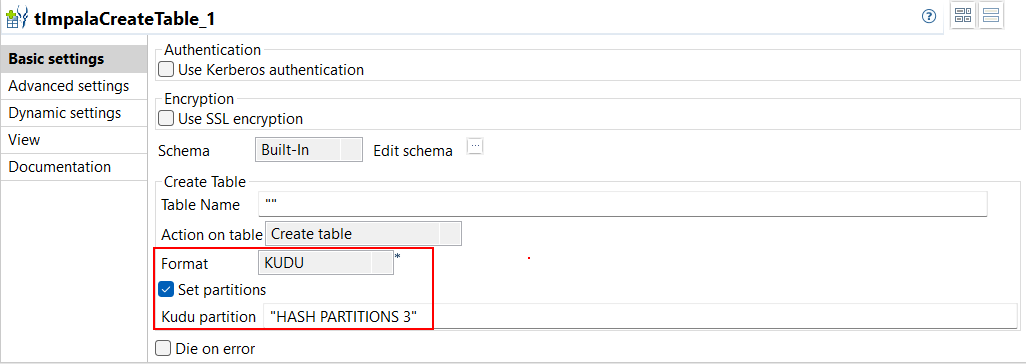
|
All subscription-based Talend products with Big Data |
| New component tHBaseDeleteRow to delete rows from an HBase table in Standard Jobs | A new component, tHBaseDeleteRow, is available in your Standard Jobs. This
component allows you to delete rows with data from an HBase table by providing
row keys.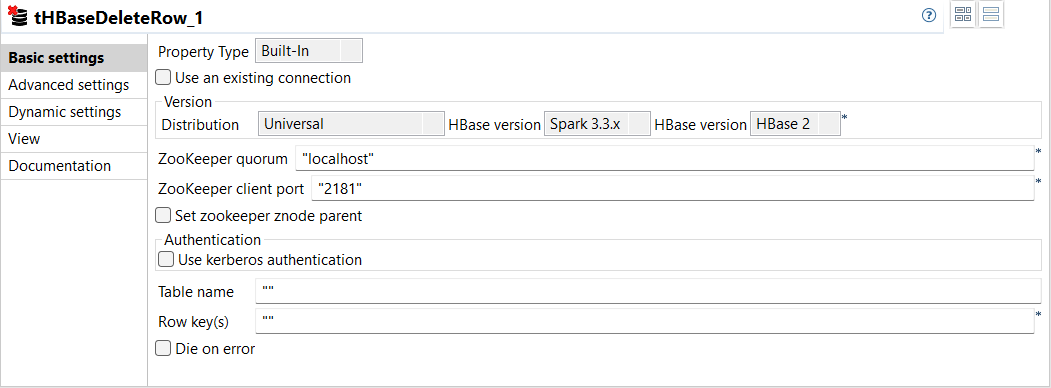
|
All subscription-based Talend products with Big Data |
| Ability to run Spark Batch Jobs with HBase components using Knox with CDP Public Cloud | You can use Knox with HBase in your Spark Batch Jobs running on CDP Public Cloud. You can configure Knox either in the tHBaseConfiguration parameters or in the HBase metadata wizard. |
All subscription-based Talend products with Big Data |
| Support for parallel reading from HBase table in Spark Batch Jobs | A new option Partition by table regions is available
in the Basic settings view of tHBaseInput in your Spark
Batch Jobs. This option allows you to read in parallel the data from an HBase
table using its number of regions.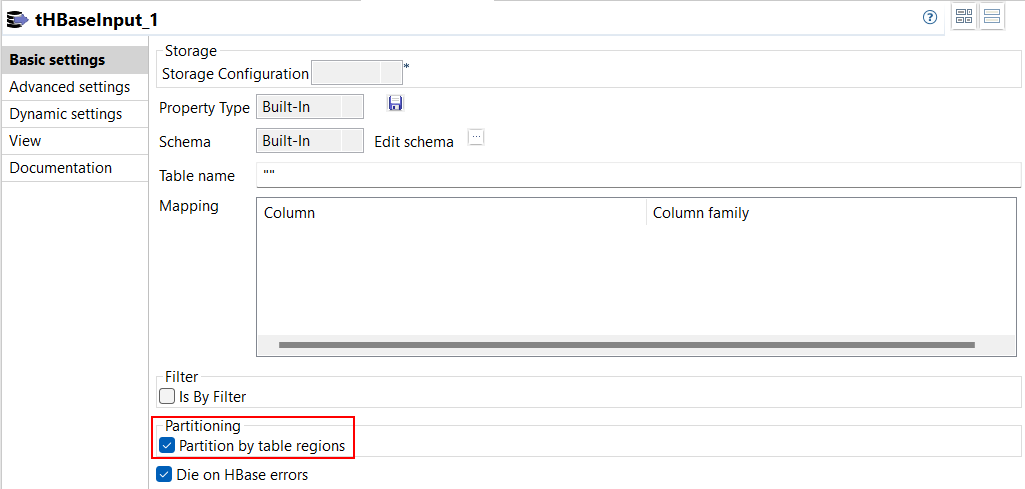
|
All subscription-based Talend products with Big Data |
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!