
Big Data
|
Fonctionnalité |
Description |
Disponible dans |
|---|---|---|
| Nouveau composant tManagePartitions permettant de gérer des partitions de jeux de données Spark dans des Jobs Spark Batch | Un nouveau composant, le tManagePartitions, est disponible dans vos Jobs Spark Batch. Il remplace le tPartition, qui est déprécié. Ce composant vous permet de gérer vos partitions en définissant visuellement la manière dont un jeu de données d'entrée est partitionné.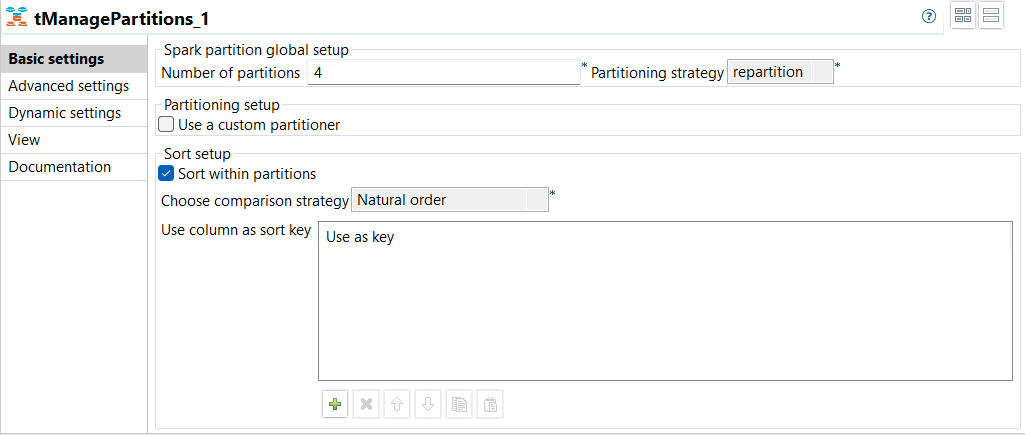
|
Tous les produits Talend avec Big Data nécessitant souscription |
| Support du partitionnement automatique avec le tManagePartitions dans des Jobs Spark Batch | Une nouvelle option Auto est disponible dans la liste déroulante Partitioning strategy (Stratégie du partitionnement) de la vue Basic settings (Paramètres simples) du tManagePartitions dans vos Jobs Spark. Cette option vous permet de calculer la meilleure stratégie à appliquer sur un jeu de données. 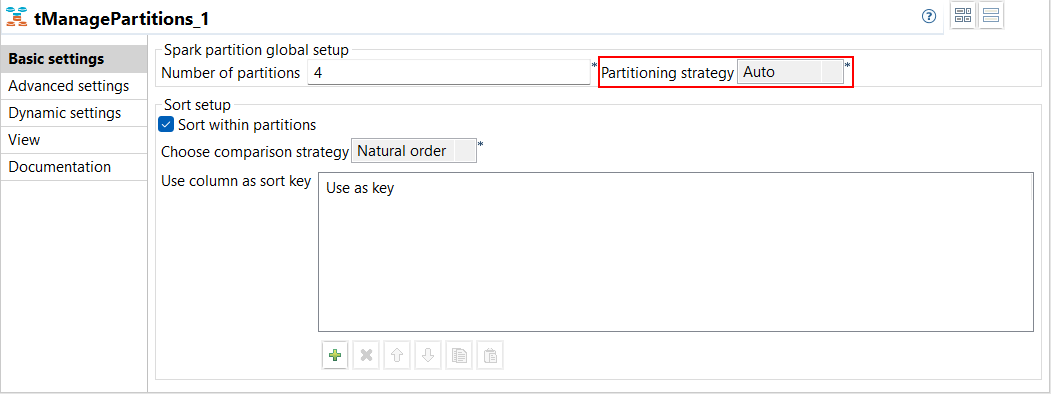
|
Tous les produits Talend avec Big Data nécessitant souscription |
| Nouveau composant tCacheClear permettant de vider le cache Spark dans des Jobs Spark Batch | Un nouveau composent, le tCacheClear, est disponible dans vos Jobs Spark Batch. Ce composant vous permet de supprimer de la mémoire le cache RDD (Resilient Distributed Datasets) stocké par le tCacheOut. Vider le cache est une bonne pratique. Par exemple, lorsque la couche de cache est pleine, Spark commence à détruire les données de la mémoire à l'aide de la stratégie LRU (least recently used, utilisation la moins récente). Ainsi, ne pas faire persister les données vous permet de rester en contrôle des données supprimées. Plus il y a d'espace dans la mémoire, plus elle peut être utilisée par Spark pour l'exécution, par exemple pour construire des maps de hachage |
Tous les produits Talend avec Big Data nécessitant souscription |
| Support du format Kudu avec le tImpalaCreateTable dans des Jobs Standard | Le format Kudu est supporté lors de la création d'une table avec le tImpalaCreateTable dans vos Jobs Standard. Lorsque vous travaillez avec une table Kudu, vous pouvez également configurer le nombre de partitions à créer avec le nouveau paramètre Kudu partition (Partition Kudu).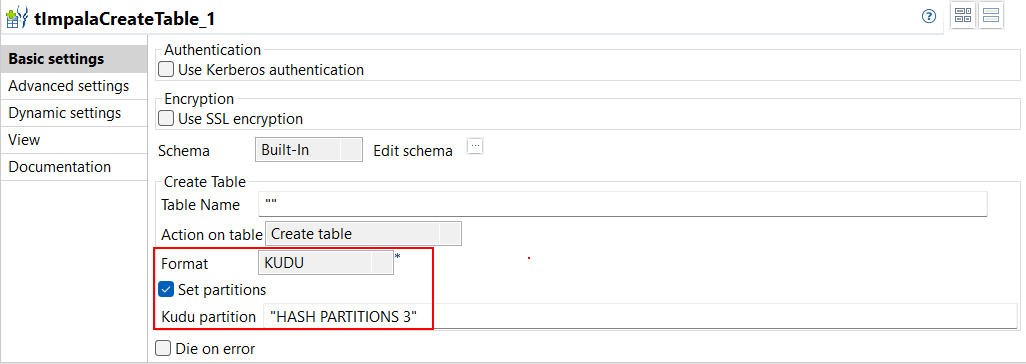
|
Tous les produits Talend avec Big Data nécessitant souscription |
| Nouveau composant tHBaseDeleteRow permettant de supprimer des lignes depuis une table HBase dans des Jobs Standard | Un nouveau composant, le HBaseDeleteRow, est disponible dans vos Jobs Standard. Ce composant vous permet de supprimer les lignes contenant des données provenant d'une table HBase en fournissant de nouvelles clés de lignes.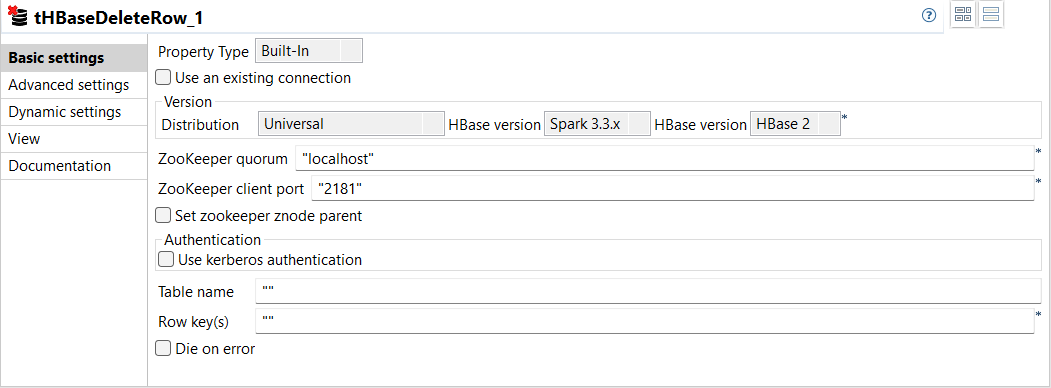
|
Tous les produits Talend avec Big Data nécessitant souscription |
| Possibilité d'exécuter des Jobs Spark Batch avec les composants HBase en utilisant Knox avec CDP Public Cloud | Vous pouvez utiliser Knox avec HBase dans vos Jobs Spark Batch s'exécutant sur CDP Public Cloud. Vous pouvez configurer Knox dans les paramètres du tHBaseConfiguration ou dans l'assistant de métadonnées HBase. |
Tous les produits Talend avec Big Data nécessitant souscription |
| Support de la lecture parallèle depuis une table HBase dans des Jobs Spark Batch | Une nouvelle option Partition by table regions (Partitionner par régions des tables) est disponible dans la vue Basic settings (Paramètres simples) du tHBaseInput dans vos Jobs Spark Batch. Cette option vous permet de lire en parallèle les données d'une table HBase à l'aide de ses régions.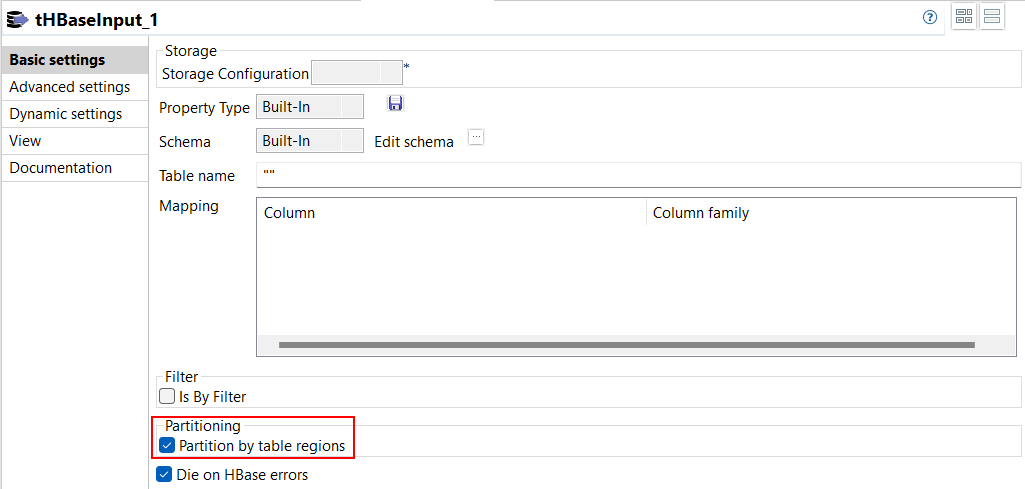
|
Tous les produits Talend avec Big Data nécessitant souscription |
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !