
Assigning Remote Engines to clusters
Before you begin
About this task
Information noteNote: If a Route or data service
is deployed on an engine you want to add to the cluster, you must first undeploy the
task, then add the engine to the cluster and redeploy the task on the engine
cluster.
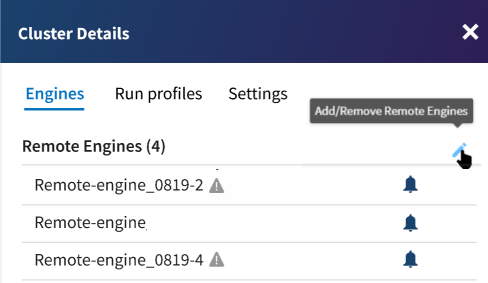
Procedure
-
Click the
 icon on the Engines tab.
icon on the Engines tab.
Example
Results
The number of engines belonging to a cluster appears in brackets next to its name on the Engines tab of the Processing page.
When choosing to run a Job task on the cluster, it is executed in a round-robin manner on the engines belonging to the cluster. The task is executed on the first available Remote Engine, then the next and so on, while putting the ones the task was executed on to the end of the list. If a Remote Engine is not available, the task is executed on the next available engine.
When choosing to run a data service or Route task on the cluster, you
must define a deployment strategy.
| Parallel | The tasks are deployed simultaneously to all the Remote Engines of the cluster. Before deploying a new version of a task, you will need to undeploy the currently running version, which will result in service interruption. |
| Rolling | If the Remote Engine cluster contains more than one Remote Engine, the tasks are deployed one by one to the Remote Engines of the cluster. This means that for a short time, different Remote Engines will be running different versions of the task, therefore you can avoid service interruption. |
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!