
Enabling parallelization of data flows
In Talend Studio, parallelization of data flows means to partition an input data flow of a subJob into parallel processes and to simultaneously execute them, so as to gain better performance. These processes are executed always in a same machine.
Note that this type of parallelization is available only on the condition that you have subscribed to one of the Platform solutions or Big Data solutions.
You can use dedicated components or the Set parallelization option in the contextual menu within a Job to implement this type of parallel execution.
The dedicated components are tPartitioner, tCollector, tRecollector and tDepartitioner.
The following sections explains how to use the Set parallelization option and the related Parallelization vertical tab associated with a Row connection.
You can enable or disable the parallelization by one single click, and then Talend Studio automates the implementation across a given Job.
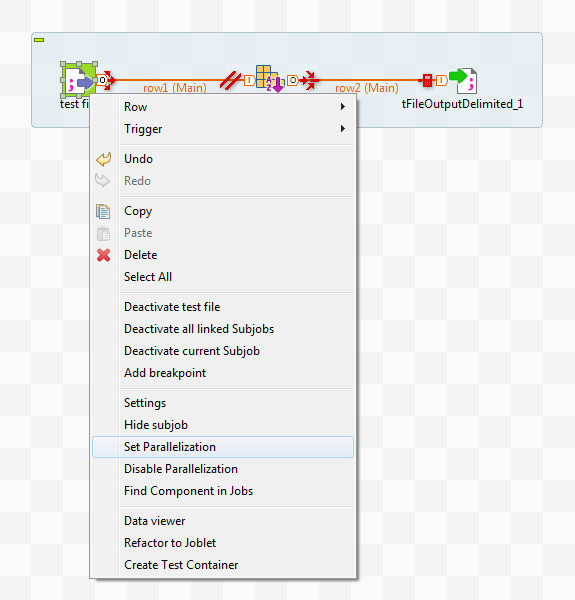
The implementation of the parallelization requires four key steps as explained as follows:
- Partitioning (
 ): In this step, Talend Studio splits
the input records into a given number of threads.
): In this step, Talend Studio splits
the input records into a given number of threads. - Collecting (
 ): In this step, Talend Studio
collects the split threads and sends them to a given component for processing.
): In this step, Talend Studio
collects the split threads and sends them to a given component for processing. - Departitioning (
 ): In this step, Talend Studio groups
the outputs of the parallel executions of the split threads.
): In this step, Talend Studio groups
the outputs of the parallel executions of the split threads. - Recollecting (
 ): In this step, Talend Studio
captures the grouped execution results and outputs them to a given component.
): In this step, Talend Studio
captures the grouped execution results and outputs them to a given component.
Once the automatic implementation is done, you can alter the default configuration by clicking the corresponding connection between components.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!