
Writing data in parallel
About this task
Note that when parallel execution is enabled, it is not possible to use global variables to retrieve return values in a subJob.
The Advanced settings for all database output components include the option Enable Parallel Execution which, if selected, allows to perform high-speed data processing, that is treating multiple data flows simultaneously.
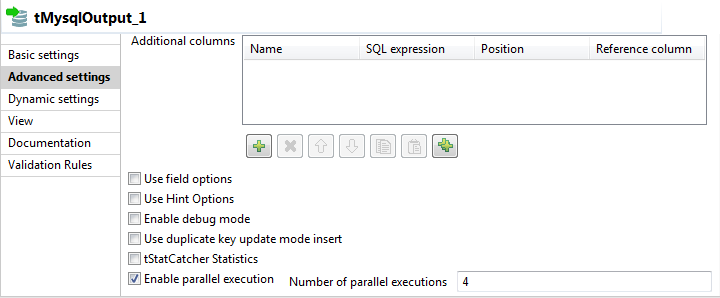
When you select the Enable parallel execution check box, the Number of parallel executions field displays where you can enter the number by which the current processed data is devised to achieve N level of parallel processings.
The current processed data being executed across N fragments might execute N times faster than it would if processed as a single fragment.
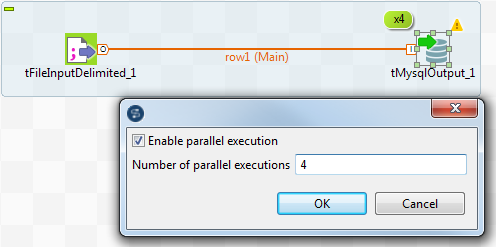
You can also set the data flow parallelization parameters from the design workspace of the Integration perspective. To do that:
Procedure
-
Select the Enable parallel execution check
box and enter the number of parallel executions in the corresponding field.
Alternatively, press Ctrl + Space and select
the appropriate context variable from the list.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!