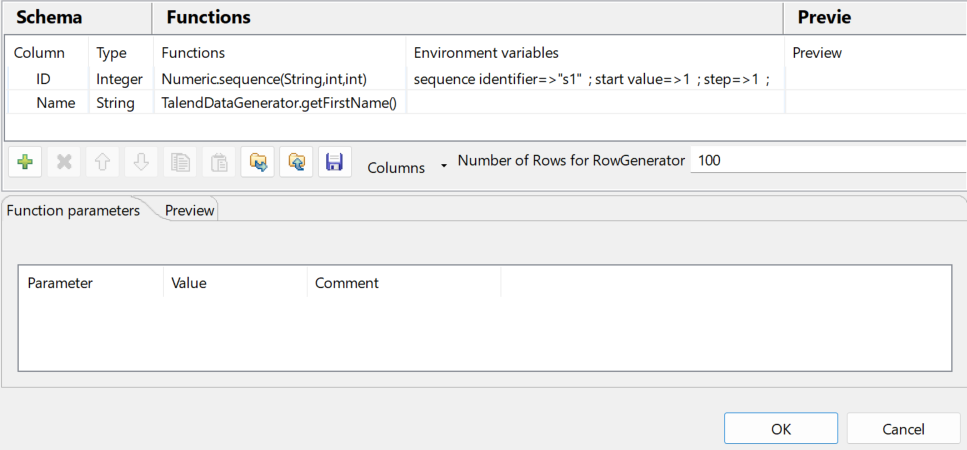
Double-cliquez sur le tRowGenerator pour ouvrir l'éditeur RowGenerator Editor.
Cliquez sur le bouton [+] pour ajouter deux colonnes : ID de type Integer et Name de type String.
Cliquez dans la cellule de la colonne Functions et sélectionnez dans la liste une fonction pour chaque colonne. Dans cet exemple, sélectionnez Numeric.sequence pour générer des nombres en séquence pour la colonne ID et sélectionnez TalendDataGenerator.getFirstName afin de générer des prénoms aléatoires pour la colonne Name.
Dans le champ Number of Rows for RowGenerator, saisissez le nombre de lignes de données à générer. Dans cet exemple, saisissez 20.
Cliquez sur OK pour fermer l'éditeur de schéma. Acceptez la propagation proposée par la boîte de dialogue qui s'ouvre.
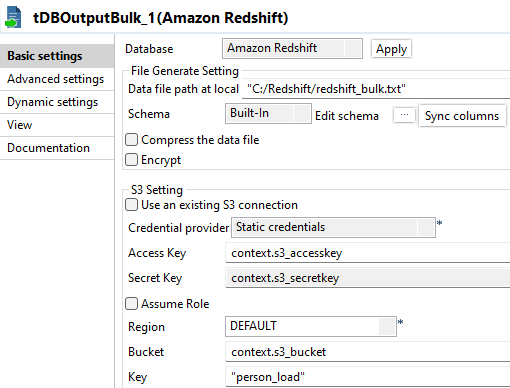
Double-cliquez sur le tRedshiftOutputBulk pour ouvrir sa vue Basic settings dans l'onglet Component.
Dans le champ Data file path at local, spécifiez le chemin local pour le fichier à générer. Dans cet exemple, le chemin est E:/Redshift/redshift_bulk.txt.
Dans le champ Access Key, appuyez sur les touches Ctrl + Espace et, dans la liste, sélectionnez context.s3_accesskey afin de renseigner ce champ.
Répétez l'opération dans le champ Secret Key avec la valeur context.s3_accesskey et dans le champ Bucket avec la valeur context.s3_bucket.
Dans le champ Key, saisissez un nouveau nom pour le fichier à générer après chargement dans Amazon S3. Dans cet exemple, saisissez person_load.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – faites-le-nous savoir.