
Bloc
Dans chaque bloc, les clés de bloc doivent avoir la même valeur. Ensuite, chacun des blocs est traité de manière indépendante.
L'utilisation de clés de bloc réduit le temps nécessaire aux algorithmes Simple VSR Matcher et T-Swoosh pour traiter les données. Par exemple, si 100 000 enregistrements sont partitionnés en 100 blocs de 1 000 enregistrements, le nombre de comparaisons est réduit d'un facteur 100. Ceci signifie que l'algorithme ira environ 100 fois plus vite.
Il est recommandé d'utiliser le tGenKey pour générer des clés de bloc et visualiser les statistiques concernant le nombre de blocs. Dans un Job, cliquez-droit sur le composant tGenKey et sélectionnez View Key Profile dans le menu contextuel afin de visualiser la distribution du nombre de blocs selon leur taille.
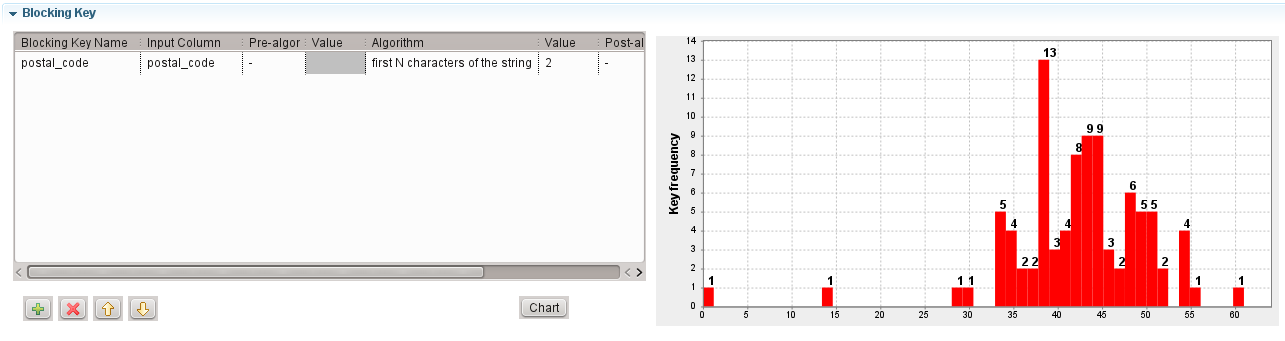
Dans cet exemple, la taille moyenne d'un bloc est d'environ 40.
Pour les 13 blocs contenant 38 lignes, il y aura 18 772 comparaisons au sein de ces 13 blocs (13 × 382). Si les enregistrements sont comparés sur quatre colonnes, il y aura 75 088 comparaisons de chaînes de caractères dans ces 13 blocs (18 772 × 4).