Calculer les paires suspectes et les enregistrements uniques
Procédure
Double-cliquez sur le premier composant tFileOutputDelimited pour afficher sa vue Basic settings et configurer ses propriétés.
Vous avez déjà accepté la propagation du schéma aux composants de sortie lorsque vous avez configuré le composant d'entrée.
Décochez la case Define a storage configuration component pour utiliser le système local comme système de fichiers cible.
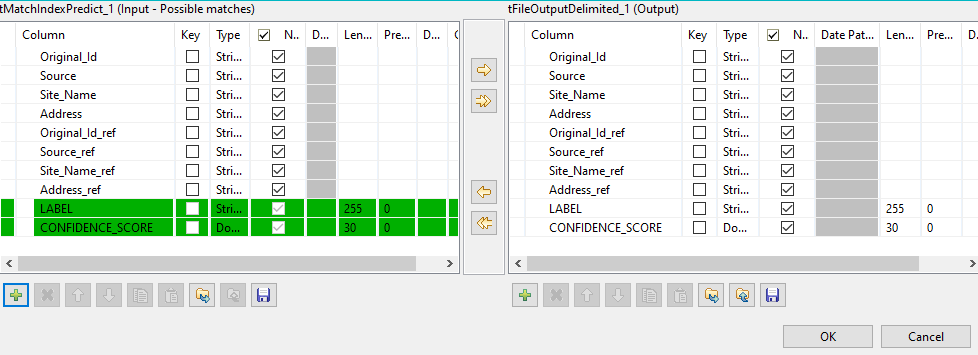
Cliquez sur [...] à côté du bouton Edit schema et utilisez le bouton [+] dans la boîte de dialogue pour ajouter les colonnes du schéma du jeu de données de références au schéma.
Vous devez ajouter _ref à la fin des noms des colonnes à ajouter à la sortie comportant les doublons suspects. Dans cet exemple : Original_id_ref, Source_ref, Site_name_ref et Address_ref.
Dans le champ Folder, configurez le chemin d'accès au dossier qui contiendra les données de sortie.
Dans la liste Action sélectionnez l'opération d'écriture de données :
sélectionnez Create lorsque vous exécutez votre Job pour la première fois ;
sélectionnez Overwrite afin de remplacer les fichiers à chaque exécution du Job.
Configurez les séparateurs de lignes et de champs dans les champs correspondants.
Cochez la case Merge results to single file et, dans le champ Merge file path, configurez le chemin vers l'emplacement où écrire le fichier des paires d'enregistrements suspects.
Double-cliquez sur le second tFileOutputDelimited et configurez ses propriétés dans la vue Basic settings, comme pour le premier composant.
Ce composant crée le fichier contenant les lignes uniques générées depuis les données d'entrée.
Appuyez sur F6 afin de sauvegarder et exécuter le Job.
Résultats
Le tMatchIndexPredict regroupe les enregistrements issus des données d'entrée et les enregistrements de correspondance, issus du jeu de données de référence stocké dans Elasticsearch, puis libelle les paires suspectes. Ils apparaissent dans la même ligne.
Le tMatchIndexPredict exclut les enregistrements uniques afin de les écrire dans un fichier séparé.
Vous pouvez maintenant nettoyer et dédoublonner les enregistrements uniques, puis utiliser le tMatchIndex afin de les ajouter au jeu de données de référence stocké dans Elasticsearch.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – faites-le-nous savoir.