
Rapprochement sur Spark
Le rapprochement dans Spark s'applique uniquement aux solutions Talend Platform avec Big Data et à Talend Data Fabric.
À l'aide du Studio Talend, vous pouvez mettre en correspondance un grand volume de données, via l'apprentissage automatique dans Spark. Cette fonctionnalité vous permet de rapprocher un grand nombre d'enregistrements, avec une intervention humaine minimale.
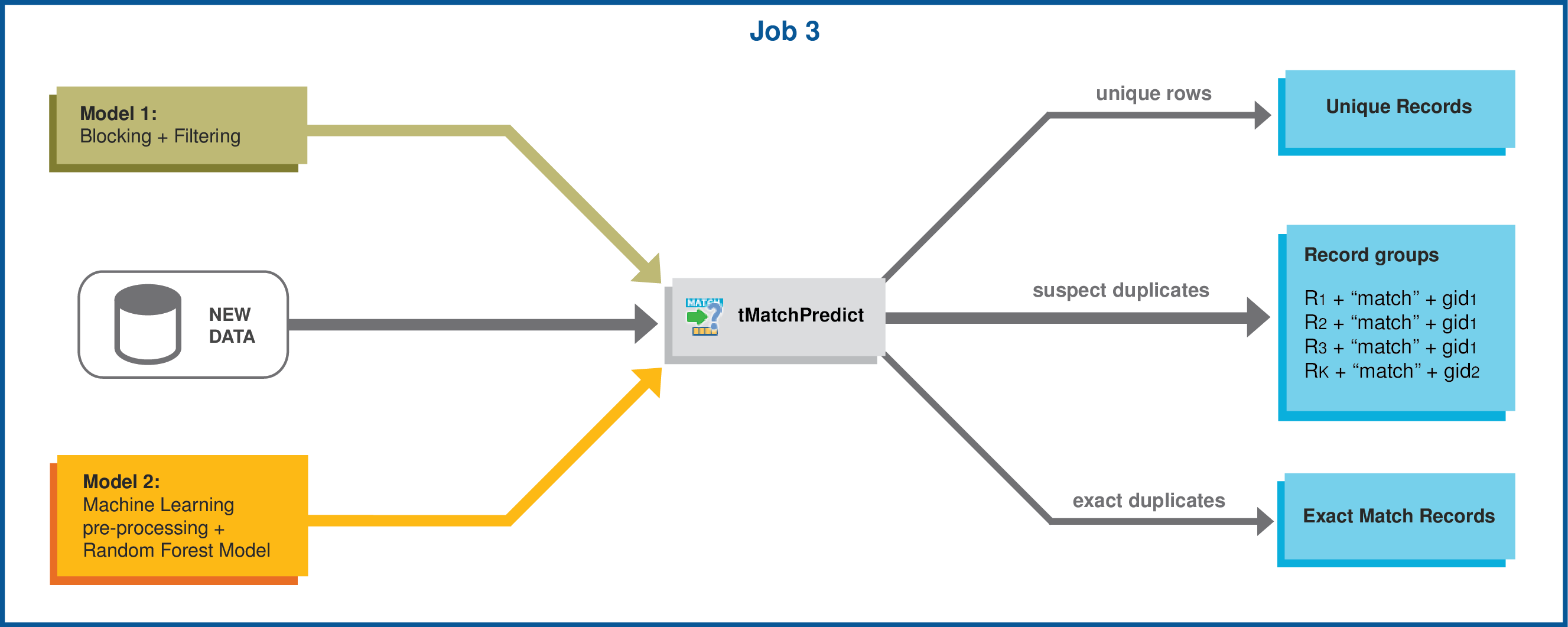
L'apprentissage automatique sur Spark se compose généralement de deux phases : la première phase calcule un modèle en se basant sur l'historique des données et les heuristiques mathématiques. La seconde phase applique le modèle sur des données textuelles. Dans le Studio Talend, la première phase est implémentée par deux Jobs, un comprenant un composant tMatchPairing et un comprenant un tMatchModel. La seconde phase est implémentée par un troisième Job contenant un tMatchPredict.
Deux workflows sont possibles lors du rapprochement dans Spark avec le Studio Talend.
-
Calcule des paires d'enregistrements suspects en se basant sur la définition d'une clé de bloc.
-
Crée un échantillon d'enregistrements suspects représentatif du jeu de données.
-
Peut, de manière facultative, écrire cet échantillon d'enregistrements suspects dans une campagne de type Grouping définie sur le serveur de Talend Data Stewardship.
-
Sépare les enregistrements uniques des enregistrements correspondant exactement,
-
génère un modèle d'appairage à utiliser avec le tMatchPredict.
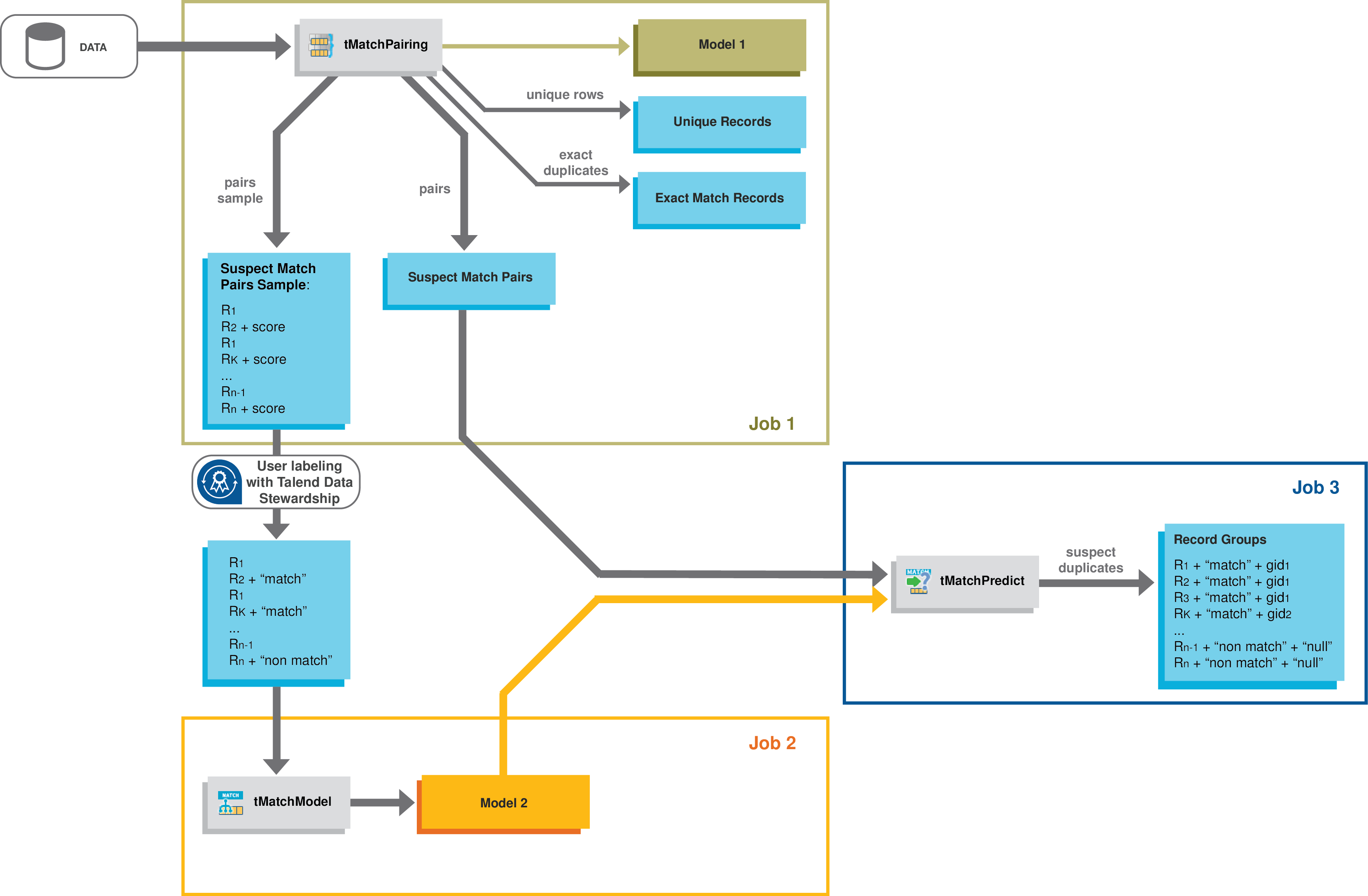
Vous pouvez manuellement libeller les enregistrements suspects de l'échantillon en résolvant les tâches d'une campagne de type Grouping définie sur le serveur de Talend Data Stewardship, ce qui constitue la méthode recommandée, ou en modifiant les fichiers manuellement.
-
calcule les similarités entre les enregistrements dans chaque paire suspecte,
-
apprend un modèle de classification en se basant sur l'algorithme Random Forest.
Le tMatchPredict libelle les enregistrements suspects automatiquement et groupe les enregistrements suspects correspondant aux libellés configurés dans les propriétés du composant.
-
libelle automatiquement les enregistrements suspects,
-
groupe les enregistrements suspects correspondant aux libellés configurés dans les propriétés du composant,
-
sépare les doublons exacts des enregistrements uniques.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !