Utiliser le filtre sur les propriétés Hadoop du Studio pour résoudre le problème de moteur Tez avec Hive pour les Jobs Spark dans une distribution Hortonworks
Procédure
-
Sélectionnez la version d'Hortonworks que vous utilisez, puis effectuez l'une des opérations suivantes :
-
Si votre distribution Hortonworks contient une installation d'Ambari, sélectionnez le bouton radio Retrieve configuration from Ambari or Cloudera et cliquez sur Next. Procédez ensuite comme suit :
-
Dans l'assistant qui s'ouvre, saisissez vos identifiants Ambari dans les champs correspondants et cliquez sur Connect.
Un nom de cluster est affiché dans la liste déroulante Discovered clusters.
-
Dans la liste, sélectionnez votre cluster et cliquez sur Fetch afin de récupérer la configuration des services relatifs.

-
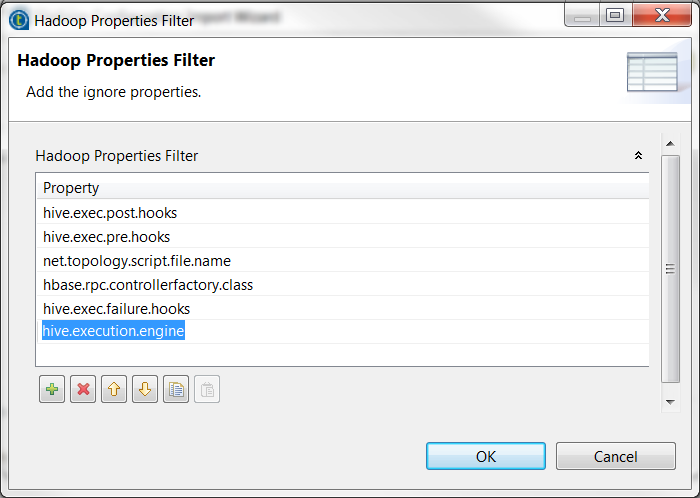
Cliquez sur le bouton [...] à côté de Hadoop property filter pour ouvrir l'assistant.
-
-
Si votre distribution Hortonworks n'a pas d'installation d'Ambari, vous devez importer les fichiers de configuration Hive depuis un répertoire local. Cela signifie que vous devez contacter l'administrateur de votre cluster pour obtenir les fichiers de configuration Hive ou que vous devez télécharger ces fichiers vous-même.
Une fois que vous avez les fichiers, procédez comme suit :
-
Dans l'assistant Hadoop configuration import wizard, sélectionnez le bouton radio Import configuration from local files et cliquez sur Next.
-
Cliquez sur Browse... pour trouver les fichiers de configuration Hive.

-
Cliquez sur le bouton [...] à côté de Hadoop property filter pour ouvrir l'assistant.
-
-
-
Cliquez sur le bouton [+] pour ajouter une ligne et saisissez hive.execution.engine dans cette ligne afin de retirer cette propriété de la liste.