
Utiliser un fichier de configuration Hive spécifique à Spark pour résoudre le problème d'utilisation d'un moteur Tez avec Hive pour des Jobs Spark dans une distribution Hortonworks
Hortonworks embarque un fichier spécifique à Spark hive-site.xml pour résoudre ce problème de moteur Tez avec Hive. Vous pouvez utiliser ce fichier afin de définir la connexion à votre cluster Hortonworks dans le Studio Talend.
Ce fichier est stocké dans le dossier de configuration Spark de votre cluster Hortonworks : /etc/spark/conf.
Procédure
-
Sélectionnez la version d'Hortonworks que vous utilisez et sélectionnez le bouton radio Import configuration from local files.
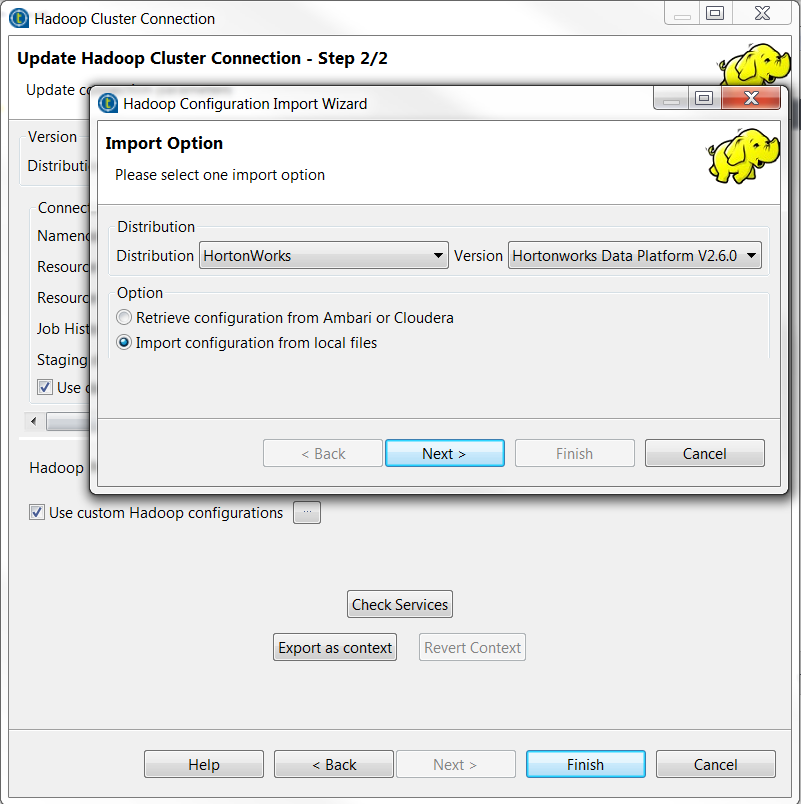
-
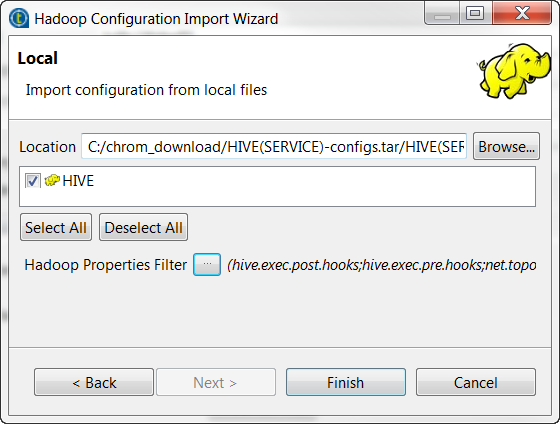
Cliquez sur Next et cliquez sur Browse... pour trouver les fichiers de configuration Hive parmi lesquels vous avez placé le fichier spécifique à Spark hive-site.xml au cours d'une précédente étape.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !