Vous pouvez générer un Job pour dédoublonner des données dans un fichier spécifique des Métadonnées du Studio Talend. Via les paramètres de ce Job automatiquement généré, vous pouvez choisir d'écrire les doublons et les valeurs uniques dans deux fichiers ou bases de données séparé(e)s.
La séquence de dédoublonnage de données dans un fichier spécifique comprend les étapes suivantes :
Sélection du fichier que vous souhaitez dédoublonner.
Choix des colonnes sur lesquelles exécuter le Job de dédoublonnage.
Si nécessaire, définition d'une clé de bloc pour partitionner les données à traiter. Une clé de bloc est généralement nécessaire lorsque le fichier comprend de nombreuses données.
Choix de l'emplacement où écrire les enregistrements uniques et en doublons.
Exécution du Job généré.
Procédure
Dans la barre de menu, sélectionnez Window > Show View.
La boîte de dialogue Show View s'ouvre.
Développez le dossier Help et sélectionnez Cheat Sheets.
Cliquez sur OK pour fermer la boîte de dialogue.
Le panneau Cheat Sheet s'affiche dans le Studio Talend.
Dans la barre d'icônes aide-mémoire, cliquez sur la flèche déroulante et dans le menu contextuel, sélectionnez Launch Other....
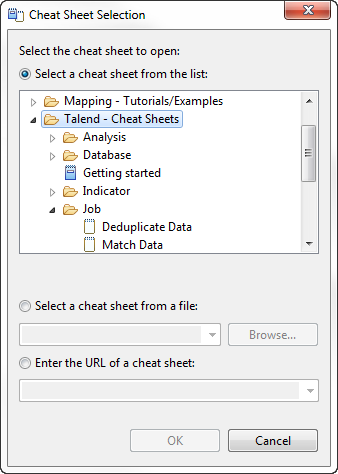
La boîte de dialogue Cheat Sheet Selection s'ouvre.
Développez Talend - Cheat Sheets > Job et sélectionnez Deduplicate Data, puis cliquez sur OK pour fermer la boîte de dialogue.
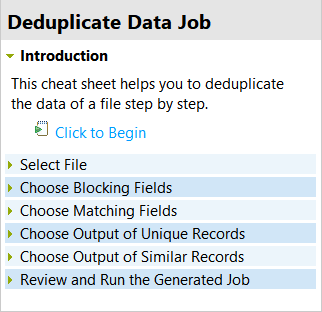
La page correspondante s'ouvre dans le panneau Cheat Sheet. Cette page vous guide à travers les étapes de création d'un Job prêt à l'emploi sur certaines colonnes d'un fichier spécifique.
Lisez l'introduction puis cliquez sur Click to Restart.
Cela va développer la première étape de la procédure : Select File (Sélectionner un fichier).
Lisez les instructions puis cliquez sur Click to perform.
L'assistant Input Type Select Dialog s'ouvre et vous guide à travers les étapes de la création du Job.
Dans le champ Type list, sélectionnez le type de fichier sur lequel vous souhaitez exécuter le Job et cliquez sur OK.
Une boîte de dialogue s'ouvre et affiche les connexions aux bases de données et fichiers définis dans le Studio Talend.
Sélectionnez le fichier à nettoyer dans la section Metadata > connections et cliquez sur OK.
L'étape suivante de l'aide-mémoire est développée.
Lisez les instructions concernant comment choisir les champs à mettre en correspondance puis cliquez sur Click to perform afin d'ouvrir la vue suivante de l'assistant.
Suivez les instructions et passez de l'assistant aux étapes dans la page des aide-mémoire jusqu'à la dernière étape : Review and Run the Generated Job.
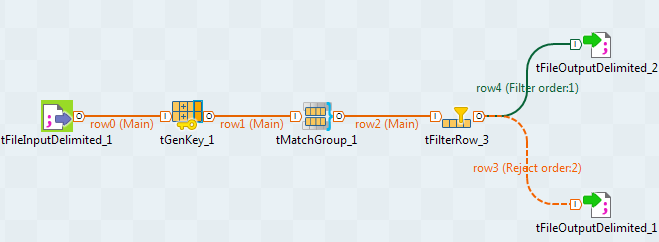
L'assistant configure tous les composants et métadonnées du Repository selon les paramètres définis dans les différentes vues de l'assistant puis génère le Job. Le Studio Talend passe à la perspective Integration afin d'afficher le Job généré devant ressembler à celui présenté dans la capture d'écran ci-dessous :
Sauvegardez le Job et appuyez sur F6 pour l'exécuter.
Résultats
Les valeurs uniques et en doublon dans le fichier sont identifiées et stockées dans les sorties définies, fichiers ou bases de données. Le Job généré est stocké sous le nœud Job Designs dans la vue Repository.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – faites-le-nous savoir.