
ジョブを保存して実行
手順
-
[F6]キーを押すか、[Run] (実行)タブの[Run] (実行)をクリックしてジョブを実行します。
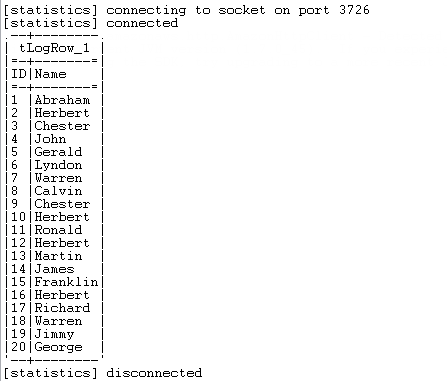
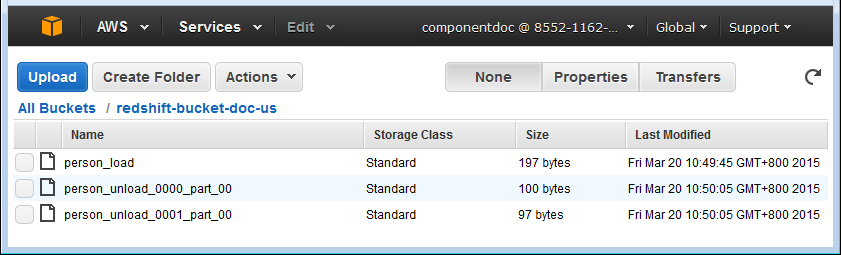
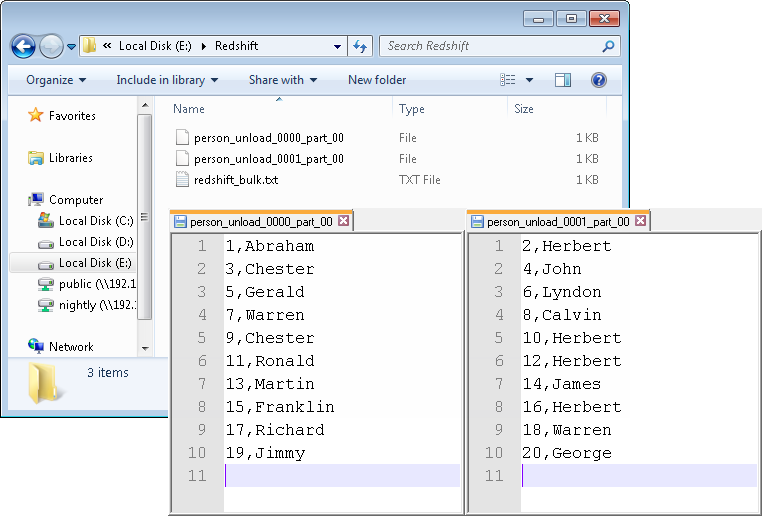 上に示すように、生成されたデータはローカルファイルredshift_bulk.txtに書き込まれ、ファイルはperson_loadという新しい名前でS3にアップロードされ、データはS3上のファイルからRedshift内のテーブルpersonにロードされ、コンソールに表示されます。その後、データはRedshiftクラスターのスライスごとにRedshift内のテーブルpersonからS3上のperson_unload_0000_part_00およびperson_unload_0001_part_00という2つのファイルにアンロードされます。最後に、S3上のアンロードされたファイルがリスト表示され、ローカルフォルダー内に取得されます。
上に示すように、生成されたデータはローカルファイルredshift_bulk.txtに書き込まれ、ファイルはperson_loadという新しい名前でS3にアップロードされ、データはS3上のファイルからRedshift内のテーブルpersonにロードされ、コンソールに表示されます。その後、データはRedshiftクラスターのスライスごとにRedshift内のテーブルpersonからS3上のperson_unload_0000_part_00およびperson_unload_0001_part_00という2つのファイルにアンロードされます。最後に、S3上のアンロードされたファイルがリスト表示され、ローカルフォルダー内に取得されます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。