
Sauvegarder et exécuter le Job
Procédure
-
Exécutez-le en appuyant sur F6 ou en cliquant sur Run dans l'onglet Run.

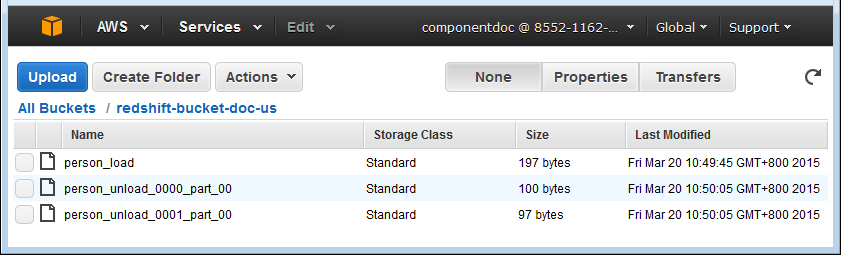
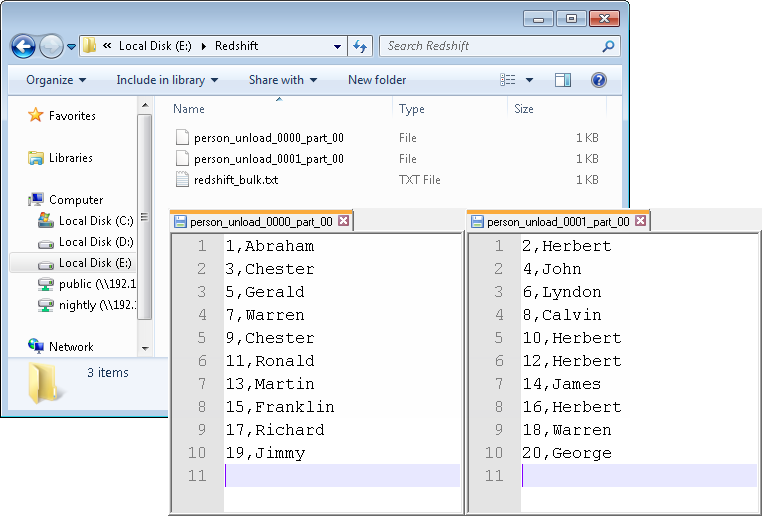 Comme affiché ci-dessus, les données générées sont écrites dans le fichier local redshift_bulk.txt. Le fichier est chargé dans S3 avec un nouveau nom, person_load. Les données sont chargées du fichier S3 dans la table person de Redshift et affichées dans la console. Les données sont ensuite retirées de la table person de Redshift et ajoutées à deux fichiers person_unload_0000_part_00 et person_unload_0001_part_00 dans S3, par slice du cluster Redshift, puis les fichiers retirés de S3 sont listés et récupérés dans le dossier local.
Comme affiché ci-dessus, les données générées sont écrites dans le fichier local redshift_bulk.txt. Le fichier est chargé dans S3 avec un nouveau nom, person_load. Les données sont chargées du fichier S3 dans la table person de Redshift et affichées dans la console. Les données sont ensuite retirées de la table person de Redshift et ajoutées à deux fichiers person_unload_0000_part_00 et person_unload_0001_part_00 dans S3, par slice du cluster Redshift, puis les fichiers retirés de S3 sont listés et récupérés dans le dossier local.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !