
テストデータを使ってデシジョンツリーモデルを実行
このセクションでは、デシジョンツリーモデルをテストする方法について説明したり、ターゲット変数がどうやって予測されるかを検証したりします。
手順
-
[tFileInputDelimited]で、テストデータをポイントするよう[Folder/File] (フォルダー/ファイル)値を変更します。
テストデータはトレーニングデータと同じスキーマがあります。唯一の違いは、コンテンツ詳細と行数です。

-
前のセクションで作成したモデルへのパスを追加します。
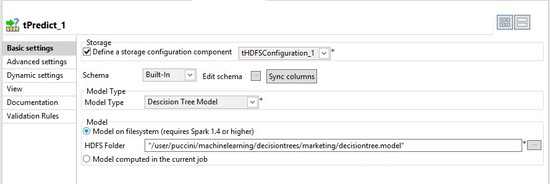
-
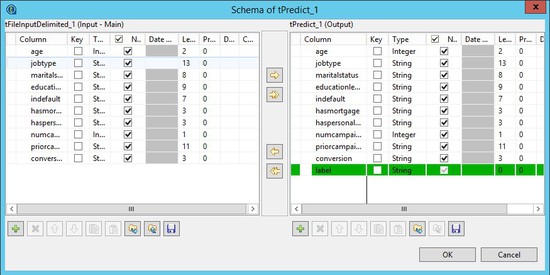
[Sync columns] (カラムを同期)ボタンをクリックした後に、省略記号をクリックして、スキーマを編集します。
出力パネルにラベルという名前の新しいカラムが追加されます。これは、デシジョンモデルによって生成された予測値のプレースホルダーです。
-
パレットに[tReplace]を追加して、[Main] (メイン)を使って、それを[tPredict]に接続します。
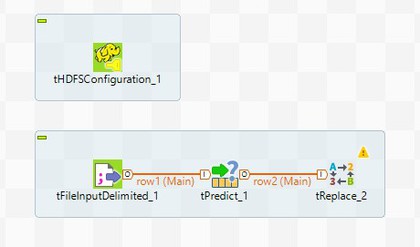
-
[tReplace]を以下のように設定します。

[tReplace]は、[tPredict]からの予測結果をブール値表記(0.0,10)からテストデータの表記(はい/いいえ)に変換するのに必要です。
-
[tAggregateRow]を以下のように設定します。
[Operation] (操作)セクションの[Output] (出力)カラムはランダムに選ばれています。ageは、[Group by] (グループ基準)のカウントを容易にするためだけのもので、それ以外の特別な理由で選ばれたものではありません。
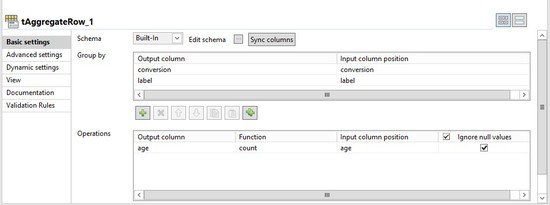
[tAggregateRow]は、次のセクションで使用されるモデルパフォーマンスの集計統計の作成に使われます。
-
パレットに[tLogRow]を追加して、それに[tAggregateRow]を接続します。
ジョブは次のように表示されるはずです。
タスクの結果
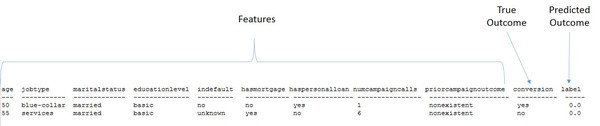
このジョブの想定される結果は、モデル予測を現在の正しい結果に対して示す概要テーブルです。

| count (年齢) | conversion (実際の結果) | label (予測される結果) |
|---|---|---|
| 41 | yes | no |
| 12 | no | yes |
| 15 | yes | yes |
| 446 | no | no |
合計514件のテストレコードに対して、出力から以下のことがわかります:
- このモデルは、テストケースのうち41件について(conversion = no)をtrueと誤って予測した
- このモデルは、テストケースのうち12件について(conversion = no)をfalseと誤って予測した
- このモデルは、テストケースのうち15件について(conversion = no)をtrueと正確に予測した
- このモデルは、テストケースのうち446件について(conversion = no)をtrueと正確に予測した
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。