
Lecture et écriture de données Avro depuis Kafka à l'aide de Jobs Standards
Ce scénario présente comment utiliser le registre du schéma avec un désérialiseur et comment gérer des données Avro en utilisant ConsumerRecord et ProducerRecord depuis les composants Apache Kafka dans vos Jobs Standards.
Pour plus de technologies supportées par Talend, consultez Composants Talend.
Dans ce scénario, créez d'abord un Job Standard pour lire des données Avro à l'aide de ConsumerRecord appelé le Job de lecture :
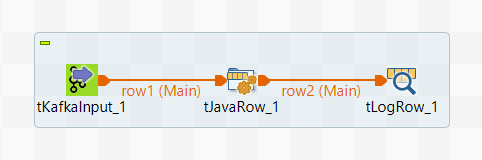
Créez ensuite un autre Job Standard pour écrire des données Avro à l'aide de ProducerRecord appelé le Job d'écriture :
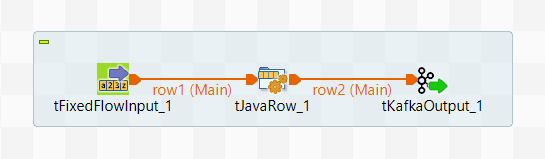
Ce scénario s'applique uniquement aux produits Talend avec Big Data et à Talend Data Fabric.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !