
パイプラインの作成
パイプラインを最初から作成する方法について説明します。
手順
-
 アイコンをクリックして、必要に応じて1つまたは複数の処理コンポーネント(フィルタリング、クレンジング、集計など)を選択します。
[Add a processor] (プロセッサーを追加)パネルでは、メインリストからプロセッサーを選択するか、テキストボックスに名前や説明を入力できます。
アイコンをクリックして、必要に応じて1つまたは複数の処理コンポーネント(フィルタリング、クレンジング、集計など)を選択します。
[Add a processor] (プロセッサーを追加)パネルでは、メインリストからプロセッサーを選択するか、テキストボックスに名前や説明を入力できます。 -
デスティネーションデータセットを選択します:
- データセットを既に作成している場合は、[Select a destination] (デスティネーションを選択)パネルのリストでそのデータセットを選択して[Select] (選択)をクリックします。
- 作成していない場合は、データセットを最初から作成の説明に従い、[Add dataset] (データセットを追加)をクリックして新しいデータセットを追加します。
パイプラインがS3入力からデータを消費し、データを処理およびフィルタリングして、選択されたデータを別のS3デスティネーションに送信する例。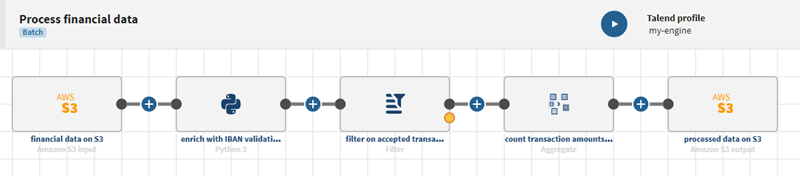
パイプラインを実行する前には、デザインプロセスの各ステップでデータのプレビューを確認できます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。