
HDFS接続でビッグデータバッチジョブを作成
Hadoopクラスターとストラクチャーを作成した後は、tHDFSConfiguration、tHMapInput、tLogRowという3つのコンポーネントを含んでいるビッグデータバッチジョブをデザインします。
手順
-
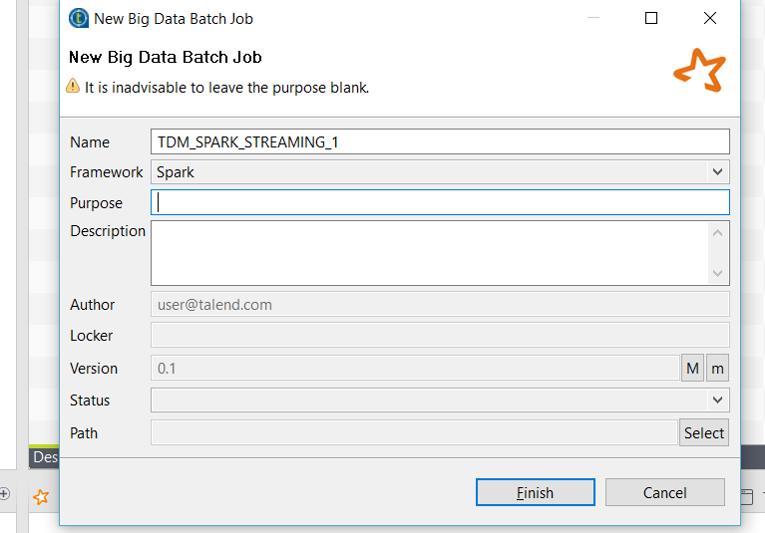
[Big Data Batch] (ビッグデータバッチ)を右クリックし、[Create Big Data Batch Job] (ビッグデータバッチジョブを作成)を選択します。
-
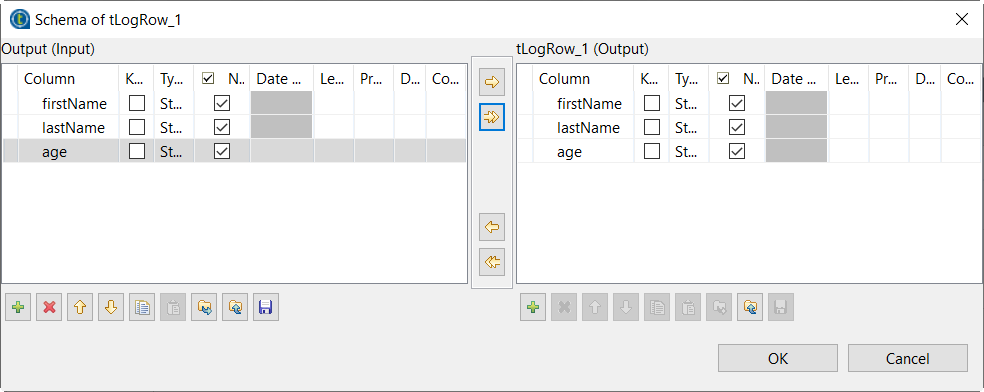
tLogRowをダブルクリックしてそのスキーマを定義します:
- [Edit schema] (スキーマを編集)の横にある[...]ボタンをクリックします。
- [Output (Input)] (出力(入力))セクションで、[ + ]をクリックしてカラムを3つ追加してそれぞれfirstName、lastName、ageという名前を付けます。
-
 ボタンをクリックし、この3つのカラムを[tLogRow_1 (Output)] (tLogRow_1 (出力))にコピーします。
ボタンをクリックし、この3つのカラムを[tLogRow_1 (Output)] (tLogRow_1 (出力))にコピーします。
-
tHMapInputをクリックし、[Basic Settings] (基本設定)タブを開きます。
-
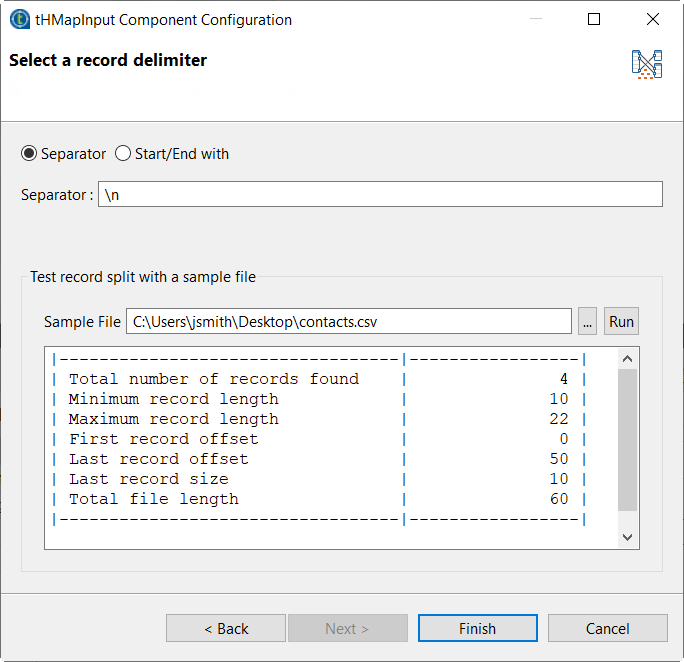
[Next] (]次へ)をクリックして[Sample File] (サンプルファイル)フィールドに入力ファイルを追加し、[Run] (実行)をクリックして検出されたレコード数を確認します。
-
[Next] (]次へ)をクリックして[Sample File] (サンプルファイル)フィールドに入力ファイルを追加し、[Run] (実行)をクリックして検出されたレコード数を確認します。