
Créer un Job Big Data Batch avec une connexion HDFS
Une fois le Cluster Hadoop et la Structure créés, définissez le Job Big Data Batch comprenant les composants tHDFSConfiguration, tHMapInput et tLogRow.
Procédure
-
Cliquez-droit sur Big Data Batch et sélectionnez Create Big Data Batch Job.

-
Double-cliquez sur le tLogRow et définissez son schéma :
- Cliquez sur le bouton [...] correspondant au champ Edit schema.
- Dans la section Output (Input), cliquez trois fois sur le bouton [+] pour ajouter trois colonnes et nommez-les firstName, lastName et age.
-
Cliquez sur le bouton
 pour copier les colonnes dans le tLogRow_1 (Output).
pour copier les colonnes dans le tLogRow_1 (Output).

-
Sélectionnez le composant tHMapInput pour ouvrir l'onglet Basic settings.
-
Cliquez sur Next et ajoutez le fichier d'entrée et, dans le champ Sample File, puis cliquez sur Run pour vérifier le nombre d'enregistrements trouvés.
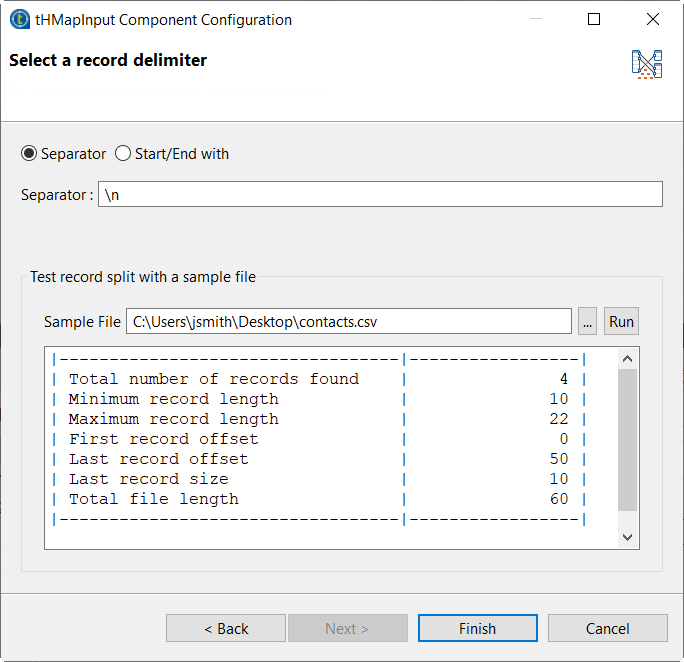
-
Cliquez sur Next et ajoutez le fichier d'entrée et, dans le champ Sample File, puis cliquez sur Run pour vérifier le nombre d'enregistrements trouvés.