
Big Data
|
Funktion |
Beschreibung |
Verfügbar in |
|---|---|---|
| Neue Komponente tManagePartitions zur Verwaltung von Spark-Datensatzpartitionen in Spark Batch-Jobs | In Ihren Spark Batch-Jobs ist jetzt die Komponente tManagePartitions verfügbar, als Ersatz für die veraltete Komponente tPartition. Diese Komponente ermöglicht Ihnen die Verwaltung Ihrer Partitionen durch die visuelle Festlegung der Art der Partitionierung eines Eingabedatensatzes.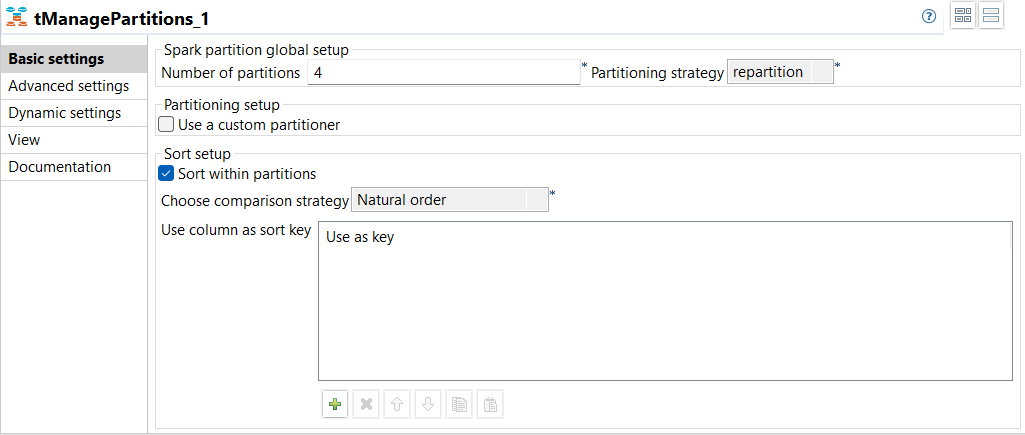
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Support für die automatische Partitionierung mit tManagePartitions in Spark Batch-Jobs | In der Dropdown-Liste Partitioning strategy (Partitionierungsstrategie) in der Ansicht Basic settings (Basiseinstellungen) von tManagePartitions in Ihren Spark-Jobs ist jetzt eine neue Option verfügbar: Auto (Autom.). Diese Option ermöglicht Ihnen die Berechnung der besten Strategie zur Anwendung auf einen Datensatz. 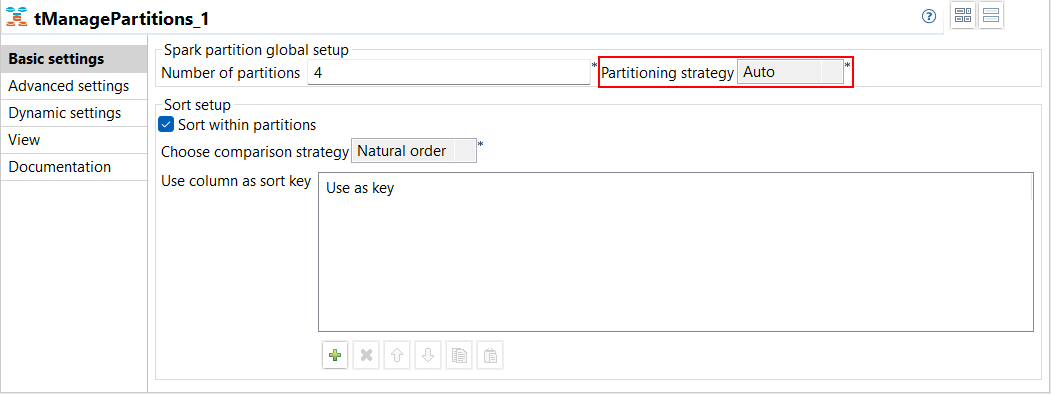
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Neue Komponente tCacheClear in Spark Batch-Jobs zum Leeren des Spark-Cachespeichers | In Ihren Spark Batch-Jobs ist jetzt eine neue Komponente verfügbar: tCacheClear. Diese Komponente ermöglicht es Ihnen, den von tCacheOut im Arbeitsspeicher genutzten RDD-Cachespeicher (Resilient Distributed Datasets) zu entfernen. Das Leeren des Cachespeichers hat sich als nützlich erwiesen. Wenn beispielsweise die Caching-Schicht gesättigt ist, beginnt Spark, die Daten anhand der LRU-Strategie (Least Recently Used: Zuletzt verwendete) aus dem Arbeitsspeicher auszulagern. Deshalb bietet Ihnen Nicht-Persistenz eine größere Kontrolle über das, was ausgelagert wird. Und je mehr Platz im Arbeitsspeicher zur Verfügung steht, umso mehr Speicher kann Spark für Ausführungen nutzen, z. B. für die Generierung von HashMaps. |
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Support für das Kudu-Format mit tImpalaCreateTable in Standard-Jobs | Bei der Erstellung einer Tabelle mit tImpalaCreateTable in Ihren Standard-Jobs wird jetzt das Kudu-Format unterstützt. Wenn Sie eine Kudu-Tabelle verwenden, ,können Sie über den neuen Parameter Kudu partition (Kudu-Partition) ebenfalls die Anzahl der zu erstellenden Partitionen konfigurieren.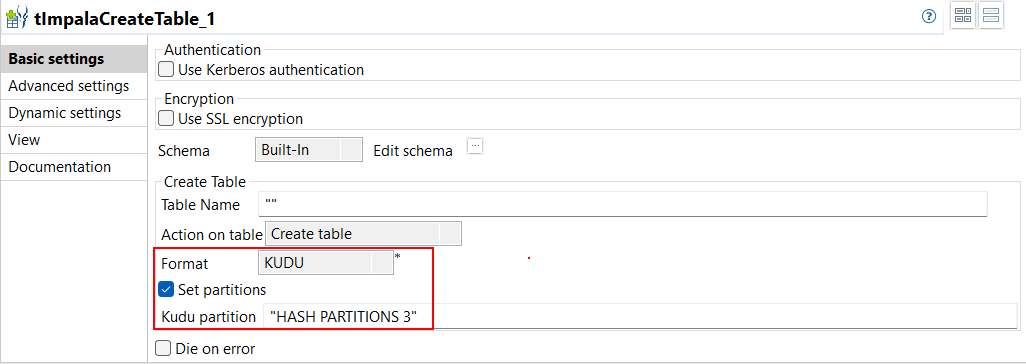
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Neue Komponente tHBaseDeleteRow zum Löschen von Zeilen in einer HBase-Tabelle in Standard-Jobs | In Ihren Standard-Jobs ist jetzt eine neue Komponente verfügbar: tHBaseDeleteRow. Diese Komponente ermöglicht Ihnen das Löschen von Zeilen mit Daten aus einer HBase-Tabelle durch Angabe der entsprechenden Zeilenschlüssel.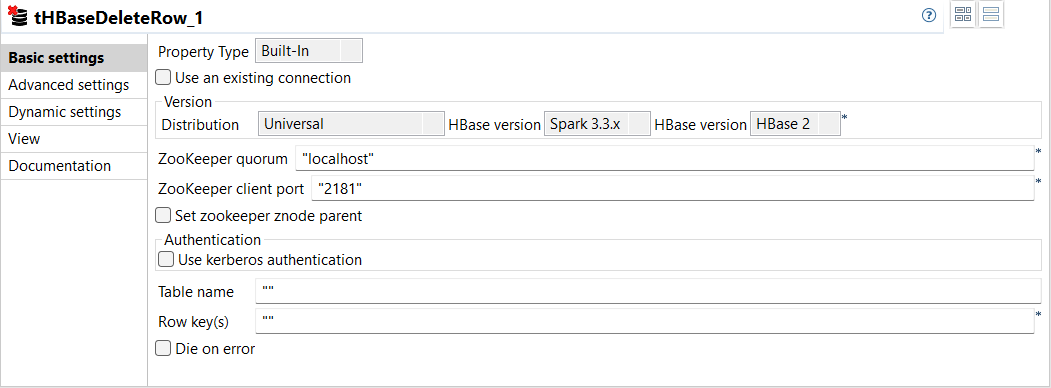
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Möglichkeit zur Ausführung von Spark Batch-Jobs mit HBase-Komponenten unter Verwendung von Knox mit CDP Public Cloud | Bei der Ausführung von Spark Batch-Jobs in CDP Public Cloud können Sie jetzt Knox mit HBase verwenden. Sie können Knox entweder in den tHBaseConfiguration-Parametern oder im HBase-Metadaten-Assistenten konfigurieren. |
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Support für paralleles Auslesen aus HBase-Tabellen in Spark Batch-Jobs | In der Ansicht Basic settings (Basiseinstellungen) von tHBaseInput in Ihren Spark Batch-Jobs ist jetzt eine neue Option verfügbar: Partition by table regions (Partitionierung nach Tabellenregionen). Diese Option ermöglicht Ihnen das parallele Lesen von Daten aus einer HBase-Tabelle anhand der jeweiligen Regionsnummern.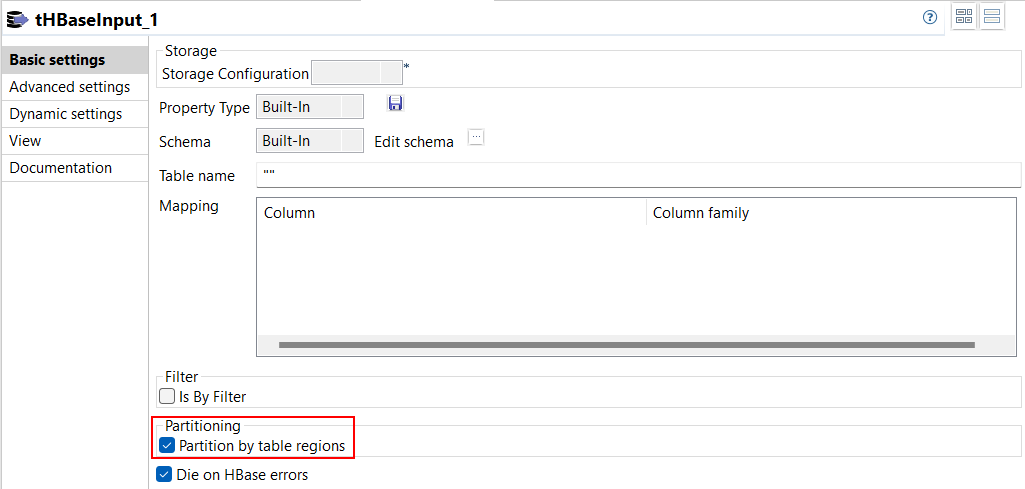
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!