
Mapping der Datenaufbereitungs- und Zielspalten
Der Mapping-Schritt ermöglicht Ihnen die Zuordnung der Spalten vor dem Schreiben in ein vorgegebenes Ziel.
Um das Mapping zu starten, stehen Ihnen mehrere Möglichkeiten zur Auswahl:
- Ziehen Sie eine Datenaufbereitungs- auf eine Zielspalte und legen Sie sie dort ab.
- Wählen Sie eine Datenaufbereitungsspalte direkt in der Dropdown-Auswahlliste aus oder geben Sie den Spaltennamen im Auswahlbereich ein.
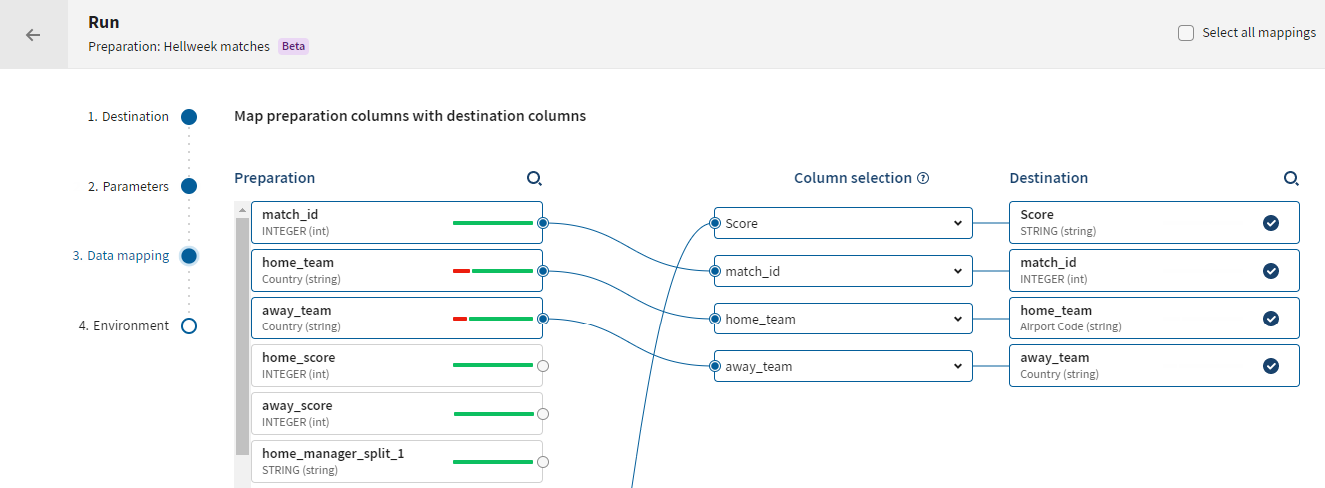
Beim Mapping von Spalten gelten die folgenden Regeln:
- Das Mapping erfolgt automatisch, sobald der zweite Schritt der Ausführungskonfiguration gestartet wird.
- Nicht zugeordnete Datenaufbereitungsspalten werden ignoriert und in den Zielspalten nicht angezeigt.
Beispiel: Ihr Aufbereitungsdatensatz enthält folgende Spalten: first_name (Name_Vorname), last_name (Name_Nachname), email (EMail) und phone (Telefon). Ihr Zieldatensatz enthält folgende Felder: firstname (Vorname), lastname (Nachname), address (Adresse) und phone (Telefon).
Wenn Sie die Spalte first_name (Name_Vorname) der Spalte firstname (Vorname), die Spalte last_name (Name_Nachname) der Spalte lastname (Nachname) und die Spalte phone (Telefon) der Spalte phone (Telefon) zuordnen, enthält der Zieldatensatz folgende Spalten: firstname (Vorname), lastname (Nachname), address (Adresse) und phone (Telefon). Die nicht zugeordnete Spalte email (EMail) wird ignoriert. Die Zielspalte address (Adresse) ist leer.
- Wenn eine obligatorische Zielspalte nicht zugeordnet wird, hat das in den meisten Fällen einen Fehler zur Folge. Die Datenaufbereitung kann zwar nach wie vor ausgeführt werden, es kann jedoch zu Datenverlust oder weiteren Fehlern kommen. Aus diesem Grund wird empfohlen, das Mapping zuvor zu berichtigen.
- Der Zieldatensatz ist ein JDBC-Datensatz: Die Werte der zugeordneten Datenaufbereitungsspalten werden im ersten Schritt der Ausführungskonfiguration gemäß der für die Datenbank festgelegten Operation (Einfügen, Aktualisieren, Upsert, Löschen) zu den entsprechenden Zielspalten hinzugefügt.
Beispiel: Wenn Sie die Aktion Insert (Einfügen) ausgewählt haben und die Datenaufbereitungsspalte first_name (Name_Vorname) die Werte Alice und John enthält und der Zielspalte firstname (Vorname) mit den Werten Will und Alima zugeordnet wird, umfasst die Zielspalte nach dem Mapping alle diese Werte: Alice, John, Will und Alima. Dies entspricht einer Einfügeaktion.
- Beim Mapping von Spalten werden keine Änderungen am Schema vorgenommen, d. h. der Name einer Zielspalte, die einer Datenaufbereitungsspalte zugeordnet wird, wird beibehalten (der Name der Datenaufbereitungsspalte wird nicht übernommen).
Beispiel: Wenn Sie die Datenaufbereitungsspalte firstname (Vorname) der Zielspalte first_name (Name_Vorname) zuordnen, erhält die zugeordnete Zielspalte den Namen first_name (Name_Vorname).
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!