
Configuring your Job to run on the Hadoop cluster
This section explains how to configure your Job to run directly on the Hadoop cluster.
Procedure
-
Add the following Advanced properties.
 The value is specific to the distribution and version of Hadoop. This tutorial uses Hortonworks 2.4 V3, which is 2.4.0.0-169. Your entry for this parameter will be different if you do not use Hortonworks 2.4 V3.Information noteNote: When running the code on the cluster, it is crucial to ensure that there is unfettered access between the two systems. In this example, you have to ensure that the Hortonworks cluster can communicate with your instance of Talend Studio. This is necessary because Spark, even though it is running on the cluster, still needs to reference the Spark drivers shipped with Talend. Moreover, if you deploy a Spark Job into a production environment, it will be run from a Talend Job server (edge node). You also need to ensure that there is unfettered communication between it and the cluster.
The value is specific to the distribution and version of Hadoop. This tutorial uses Hortonworks 2.4 V3, which is 2.4.0.0-169. Your entry for this parameter will be different if you do not use Hortonworks 2.4 V3.Information noteNote: When running the code on the cluster, it is crucial to ensure that there is unfettered access between the two systems. In this example, you have to ensure that the Hortonworks cluster can communicate with your instance of Talend Studio. This is necessary because Spark, even though it is running on the cluster, still needs to reference the Spark drivers shipped with Talend. Moreover, if you deploy a Spark Job into a production environment, it will be run from a Talend Job server (edge node). You also need to ensure that there is unfettered communication between it and the cluster.For more information on the ports needed by each service, see the Spark Security documentation.
-
Click the Advanced settings tab and add a new JVM argument that indicates the version of Hadoop. It is the string you added as value in the previous step.

-
Click the Basic Run tab, then click Run.
When it is complete, you are prompted by a message indicating success.

-
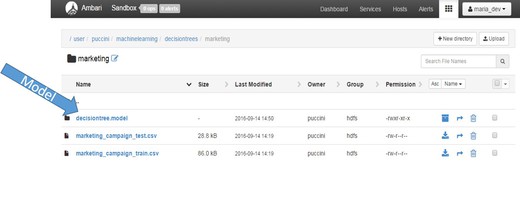
Navigate to the HDFS directory, Ambari in this case, to verify that the model was created and persisted to HDFS.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!