
Encoding training data
Procedure
-
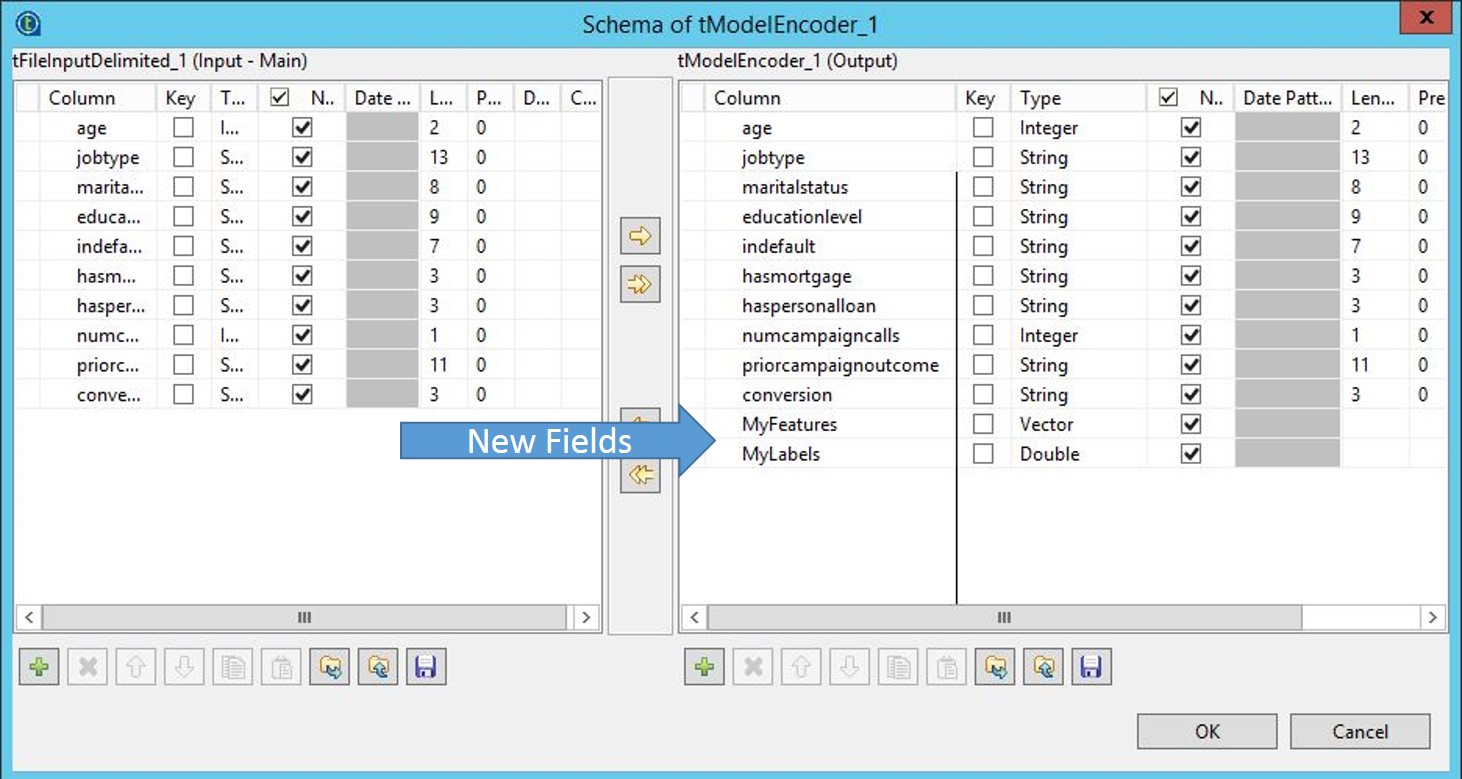
Connect tFileInputDelimited to tModelEncoder with a Main.

-
Add two new columns to the output: MyFeatures with the
type Vector and MyLabels with the
type Double.
-
Add the following code in the Parameters field.
featuresCol=MyFeatures;labelCol=MyLabels;formula=conversion ~ age + jobtype + maritalstatus + educationlevel + indefault + hasmortgage + haspersonalloan + numcampaigncalls + priorcampaignoutcome
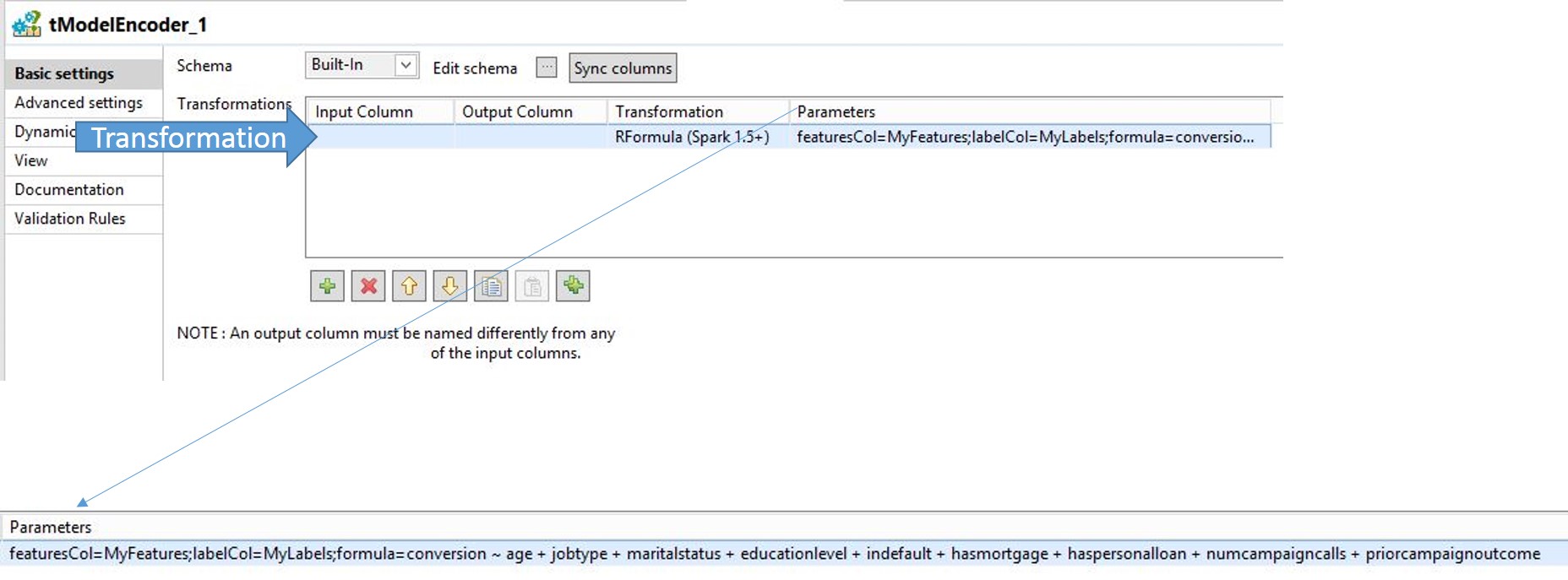
The two columns added to the schema, MyFeatures and MyLabels are referenced here. The formula is standard syntax used in the programming language R, which is used for statistical computing and advanced graphics. For more information, see The R Project.
In the sampling of the data, there were nine features and one target. In the R formula above, the target you want to predict is conversion, and it is on the left of the tilde. All columns to the right of the tilde are the features. the two remaining components, featuresCol and labelCol, are placeholders for the tuples and the feature labels.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!