
Configuring a Big Data Streaming Job using the Spark Streaming Framework
Before running your Job, you need to configure it to use your Amazon EMR
cluster.
Procedure
-
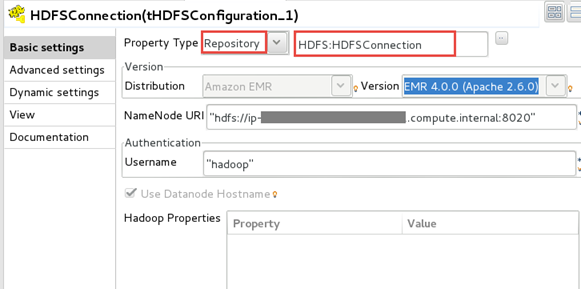
Because your Job will run on Spark, it is necessary to add a
tHDFSConfiguration component and then configure it to
use the HDFS connection metadata from the repository.
-
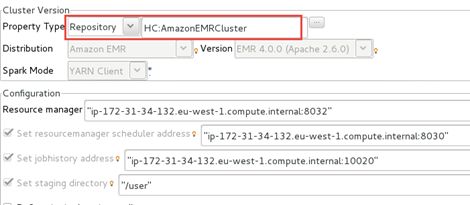
In the Cluster Version panel, configure your Job to user
your cluster connection metadata.
-
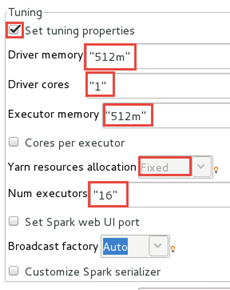
In the Tuning panel, select the Set tuning
properties option and configure the fields as follows.
-
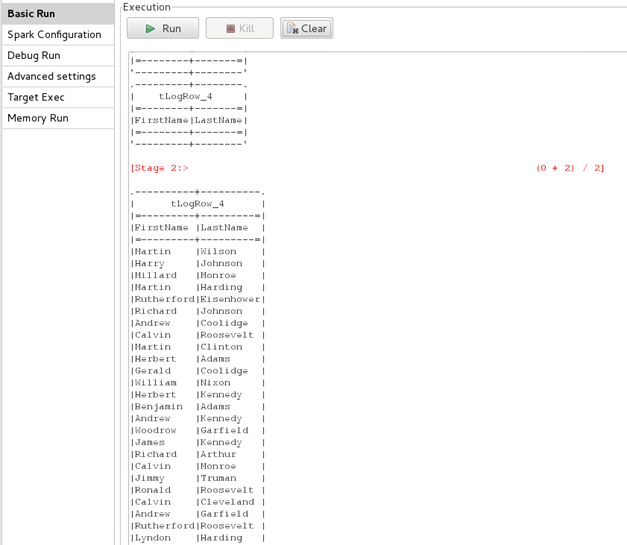
Run your Job.
It takes a couple of minutes to have data displayed in the Console.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!