
Configuration d'un Job Big Data Streaming utilisant le framework Spark Streaming
Avant d'exécuter votre Job, vous devez le configurer pour utiliser votre cluster Amazon EMR.
Procédure
-
Comme votre Job s'exécute sur Spark, il est nécessaire d'ajouter un composant tHDFSConfiguration et de le configurer pour utiliser la métadonnée de connexion à HDFS provenant du référentiel.
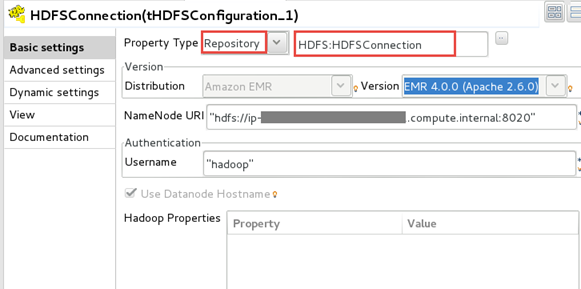
-
Dans le panneau Cluster Version, configurez votre Job pour qu'il utilise votre métadonnée de connexion au cluster.
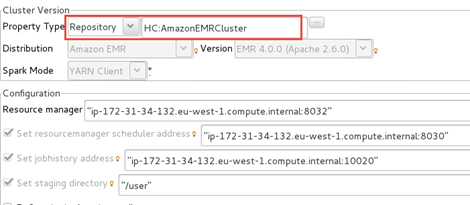
-
Dans le panneau Tuning, cochez la case Set tuning properties et configurez les champs comme suit.
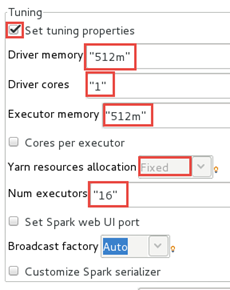
-
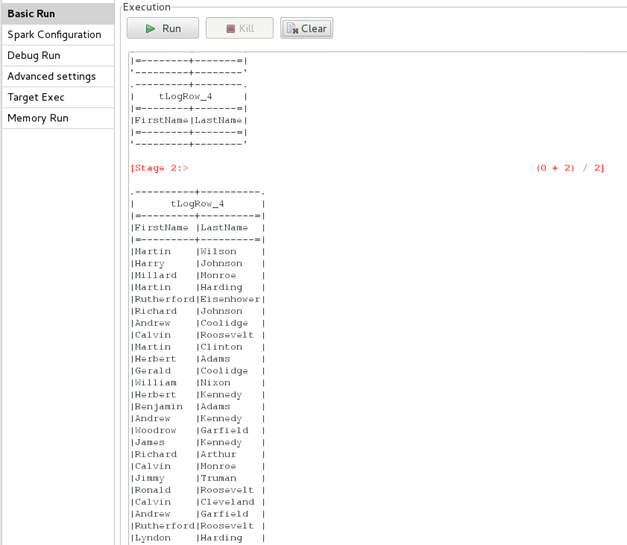
Exécutez votre Job.
L'affichage des données dans la console prend quelques minutes.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !