
Big Data: new features
|
Feature |
Description |
Available in |
|---|---|---|
| Support of Spark Universal | You can now run your Spark Jobs using Spark Universal with Spark 2.4.x or
Spark 3.0.x, either in Local or Yarn
cluster mode. Spark Universal is a mechanism that allows Talend Studio to be compatible with every big data distribution available for a given Spark version, using only a Hadoop configuration JAR file that contains all the necessary information to establish a connection to the cluster in Yarn cluster. Spark Universal gives you more agility by enabling a switch between the different Spark modes, distributions, or environments. You can configure your Spark Universal connection either
in the Spark configuration view of your Job or in the
Hadoop Cluster Connection metadata wizard from the
Repository tree view:
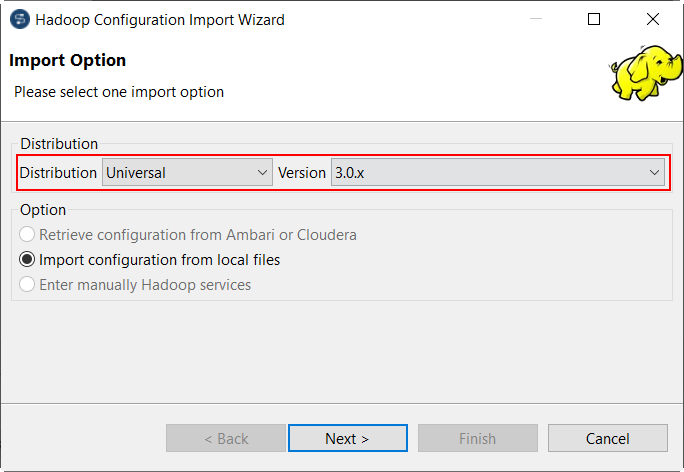
|
All subscription-based Talend products with Big Data |
| Support of Kubernetes with Spark Universal 3.1.x | You can now run your Spark Jobs using Spark Universal with Spark 3.1.x in
Kubernetes mode. You can configure your Spark
Universal connection with Kubernetes either in the Spark
configuration view of your Job or in the Hadoop
Cluster Connection metadata wizard from the
Repository tree view:
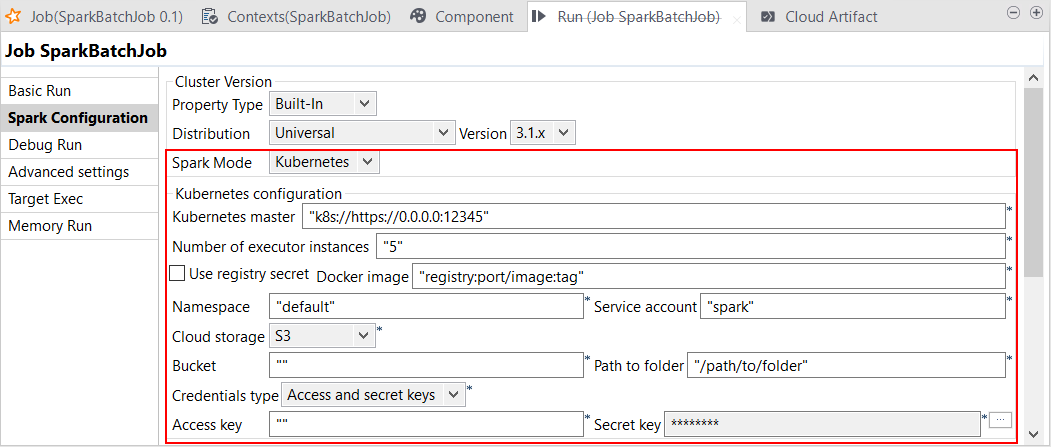
|
All subscription-based Talend products with Big Data |
| Support of Dynamic Schema in Spark Batch components | You can now use the Dynamic Schema in your Spark Jobs with the following
components:
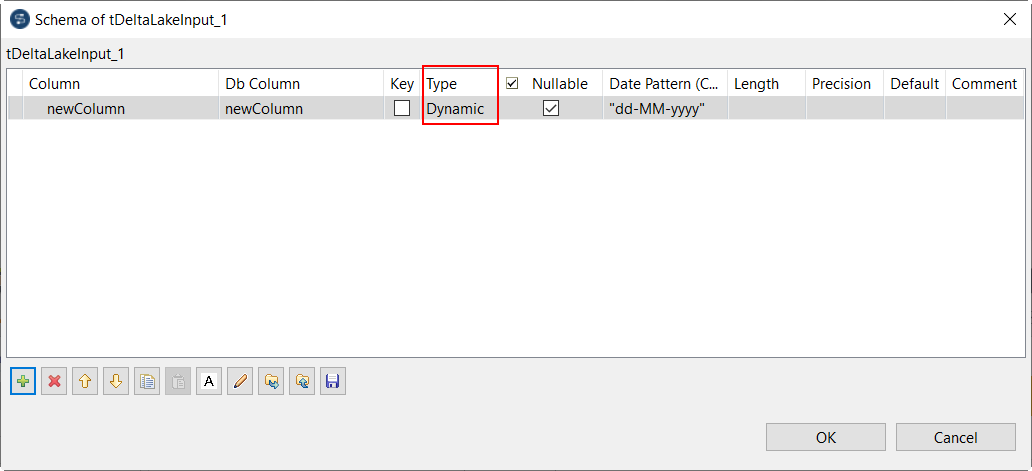
|
All subscription-based Talend products with Big Data |
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!