
Standardizing addresses from unstructured data
This scenario applies only to Talend Data Management Platform, Talend Big Data Platform, Talend Real-Time Big Data Platform, Talend MDM Platform, Talend Data Services Platform, Talend MDM Platform and Talend Data Fabric.
For more technologies supported by Talend, see Talend components.
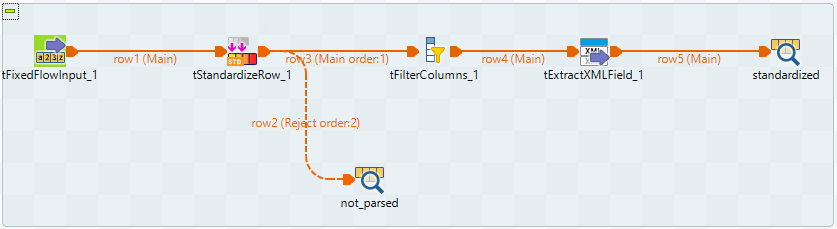
In this scenario, six components are used to standardize addresses from unstructured input data copied from a Website, by matching the data with the data contained in an index previously generated by a Job.
For more information about index creation, see tSynonymOutput.
Drop the following components from the Palette to the design workspace.
-
tFixedFlowInput: this component holds the unstructured data from which the addresses are extracted.
-
tStandardizeRow: this component defines the address rules and generates the addresses in XML format with the defined tags. This is the process of normalizing and standardizing the initially unstructured data.
-
tFilterColumns: this component filters the standardized addresses.
-
tExtractXMLField: this component extracts the attributes from the Address node of the XML tree in order to output every address item in formatted columns.
-
two tLogRow: these components are used to display the output data. The first tLogRow returns the errors, if any. The second tLogRow displays the result in the console.
Before starting up to replicate this scenario, you have to retrieve the content of an index in order to match the unstructured data with the index data. The content of the index reads as follows:
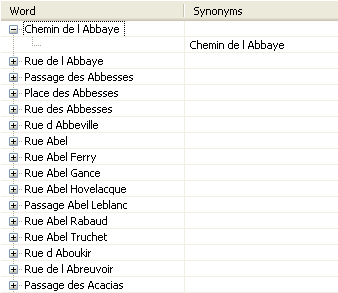
On the left side are held Paris street names and on the right side are held the synonyms used in the data. The data will be used as references to standardize the address data collected from a website.
To replicate this scenario, proceed as the following sections illustrate.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!