
Configuring the process of standardizing the unstructured data
About this task
To do this, proceed as follows:
Procedure
-
Double-click the tStandardizeRow
component to display its Basic settings
view.
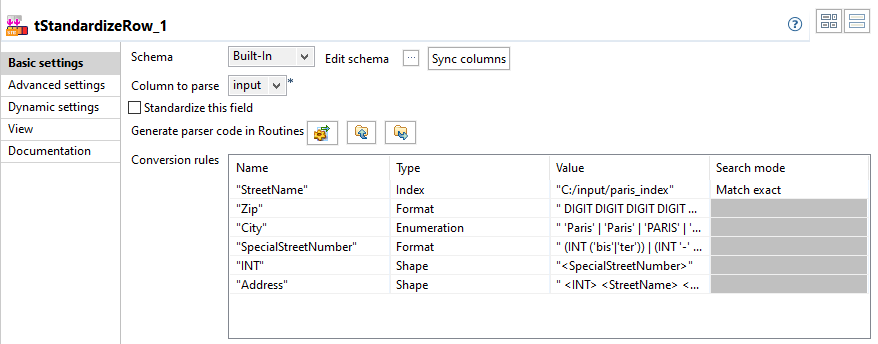 The advanced rule types are always executed after the ANTLR specific rules regardless of rule order.
The advanced rule types are always executed after the ANTLR specific rules regardless of rule order. -
Double-click the tLogRow component linked
to the tStandardizeRow component to display
its Basic settings view.
Results
Then continue to configure the process of filtering and extracting the data of interest.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!