
Crawling datasets using the dynamic selection
The dynamic crawler mode allows you to create a filter, and retrieve all the matching tables at a given time.
The main benefit of this mode is that it facilitates the discovery of tables contained in your database using filters, and you can regularly run your crawler to update your datasets quality or add new ones.
Let's take the example of a company that uses the last two digits of a given year in the names of their datasets. The tables containing the data are stored in a Snowflake database, and contain information about customers, sales, reports, etc. They want to add all the tables with data for the year 2021 to Talend Cloud Data Inventory, and be able to import any new addition or refresh the existing datasets, with a simple rerun operation.
The best way to do this is to create a Snowflake connection, and crawl it using the dynamic selection mode.
Before you begin
Procedure
-
Select the Dynamic selection mode.
All the content of the Snowflake connection is detected and listed.
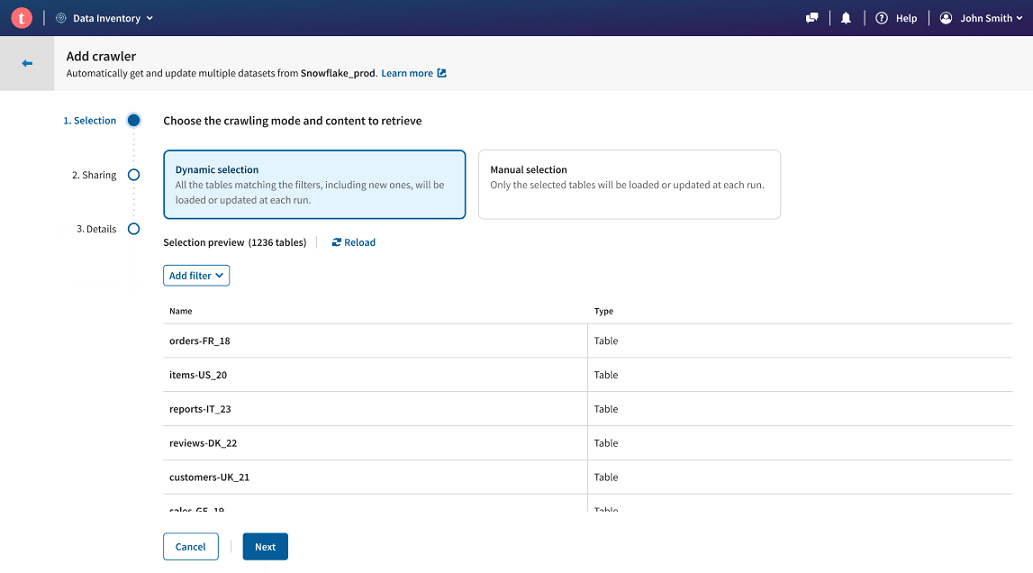
-
Click and type _21.
The selection preview now only shows the tables that contain the information from 2021.
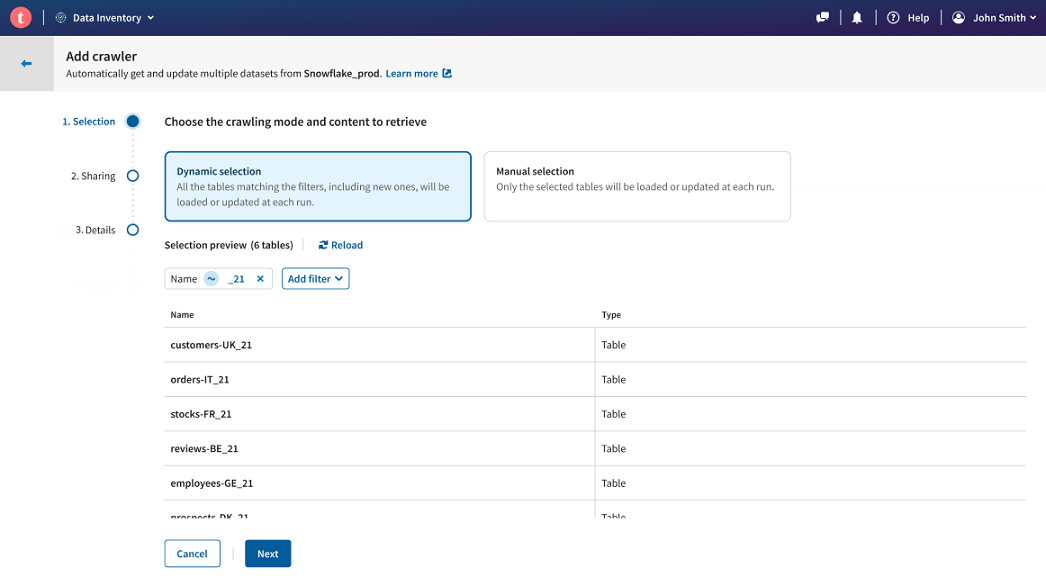 Information noteNote: Not adding any filter will select all the tables from the Snowflake database.
Information noteNote: Not adding any filter will select all the tables from the Snowflake database.
Results
Now if any change occurs in the Snowflake database, like a new table with relevant 2021 data and named with _21 made available, or some update in the data of an already existing table, then you can simply select your Snowflake connection from the connection list, and run the existing crawler again. Any new table that matches the _21 name filter will directly be added to the selection, and all the other datasets will be updated.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!