
Convertir le Job
Convertir le Job Spark Batch existant en un Job Spark Streaming.
Avant de commencer
-
Vous avez démarré le Studio Talend et ouvert la perspective Integration.
-
Vous avez créé le Job Spark Batch aggregate_movie_director_spark décrit dans Fusionner les informations relatives aux films et aux cinéastes à l'aide d'un Job Apache Spark Batch et l'avez exécuté avec succès.
Procédure
-
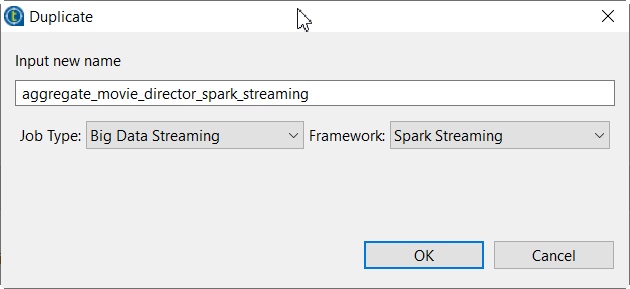
Cliquez-droit sur le Job aggregate_movie_director_spark et, dans le menu contextuel, sélectionnez Duplicate.
La fenêtre Duplicate s'ouvre.
Résultats
Ce nouveau Job Spark Streaming est prêt à être modifié.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !