
Configurer le Job parent
Procédure
-
Dans la vue Contexts :
-
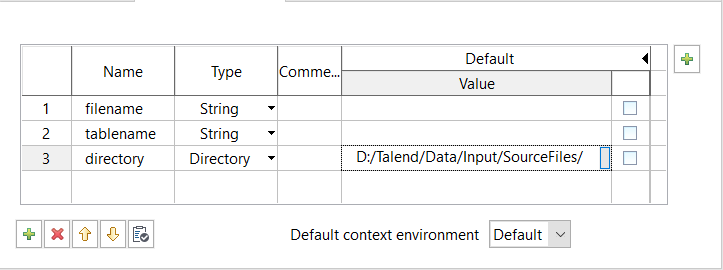
Spécifiez le répertoire en cliquant dans le champ Value de la variable directory. Cliquez sur le bouton qui apparaît et naviguez jusqu'au répertoire contenant les fichiers sources.
-
Spécifiez le répertoire en cliquant dans le champ Value de la variable directory. Cliquez sur le bouton qui apparaît et naviguez jusqu'au répertoire contenant les fichiers sources.
-
Double-cliquez sur le composant tMap pour ouvrir son éditeur de mapping, puis :
-
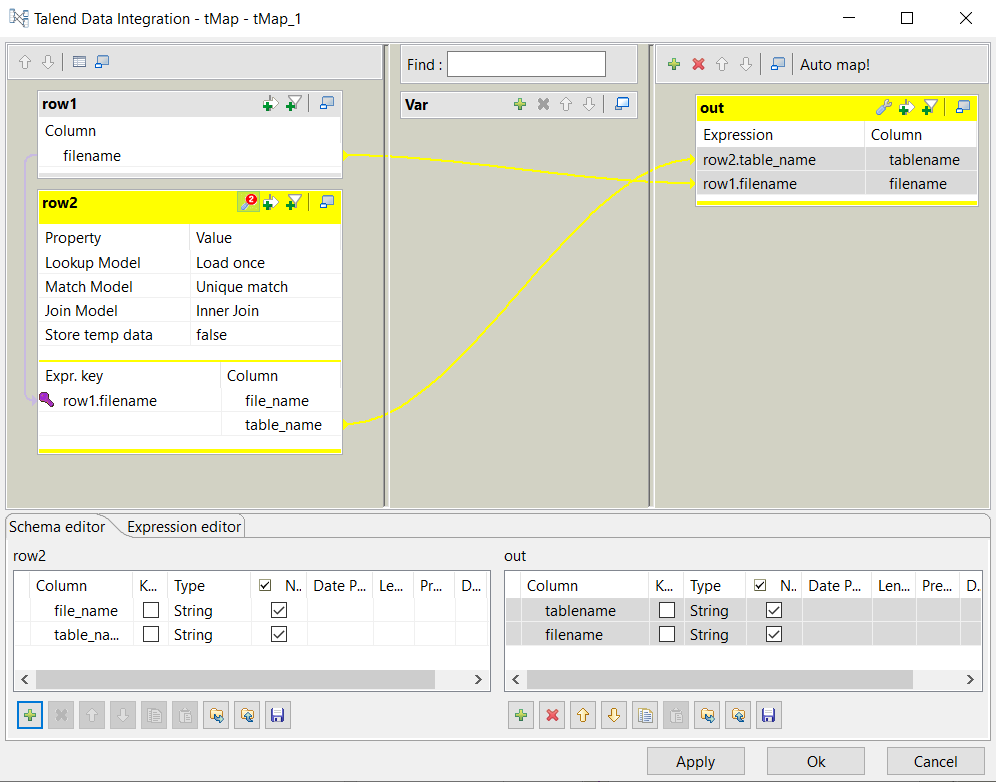
Glissez la colonne table_name de la table row2 et déposez-la dans la colonne filename de la table out.
-
Glissez la colonne table_name de la table row2 et déposez-la dans la colonne filename de la table out.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !