
Traiter des tables Lookup volumineuses
Cet article présente un cas d'utilisation spécifique et présente un moyen de gérer le problème dans le Studio Talend.
Dans ce scénario, vous avez une table source contenant des centaines de millions d'enregistrements. Ces données d'entrée sont utilisées pour effectuer un lookup sur les données d'une table contenant également des centaines de millions d'enregistrements dans une base de données différente. Les données source combinées aux données de Lookup seront insérées ou mises à jour dans une table cible.
Hypothèses
- La table source et la table Lookup ont une colonne en commun, pouvant être utilisée dans la condition de jointure.
- Les tables source et Lookup sont situées dans deux SGBD différents.
Description du problème
Vous avez un Job simple lisant des données source depuis la table cust et effectuant un lookup sur la table CUST_LOCATIONS à l'aide de la colonne location_id. Cela s'effectue dans le tMap.
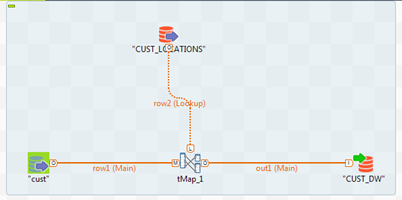
Si vous exécutez ce Job, il s'exécute et dépasse la mémoire allouée en essayant de charger les données de lookup complètes (70 millions de lignes) dans la mémoire. Ce Job fonctionne pour des petits chargements. Si vous avez des centaines de millions d'enregistrements dans la table source et la table Lookup, il est relativement inefficace.
Il est recommandé de configurer le stockage (Store) des données temporaires à true, si vous avez des lookups volumineux.
Cela ne suffit toujours pas pour ce scénario.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !