
Configurer votre Job pour une exécution sur le cluster Hadoop
Cette section explique comment configurer votre Job pour qu'il s'exécute directement sur le cluster Hadoop.
Procédure
-
Ajoutez les propriétés avancées (Advanced properties) suivantes.
 La valeur est spécifique à la distribution et à la version de Hadoop. Ce tutoriel utilise Hortonworks 2.4 V3, la version 2.4.0.0-169. Votre entrée pour ce paramètre sera différente si vous n'utilisez pas Hortonworks 2.4 V3.Note InformationsRemarque : Lorsque vous exécutez le code sur le cluster, il est crucial de vous assurer que l'accès est libre entre les deux systèmes. Dans cet exemple, vous devez vous assurer que le cluster Hortonworks peut communiquer avec votre instance du Studio Talend. Cela est nécessaire car Spark, même s'il s'exécute sur le cluster, doit faire référence aux pilotes Spark fournis avec Talend. De plus, si vous déployez un Job Spark dans un environnement de production, il sera exécuté depuis un serveur de Jobs Talend (nœud de périphérie, edge node). Vous devez également vous assurer que la communication est libre entre lui et le cluster.
La valeur est spécifique à la distribution et à la version de Hadoop. Ce tutoriel utilise Hortonworks 2.4 V3, la version 2.4.0.0-169. Votre entrée pour ce paramètre sera différente si vous n'utilisez pas Hortonworks 2.4 V3.Note InformationsRemarque : Lorsque vous exécutez le code sur le cluster, il est crucial de vous assurer que l'accès est libre entre les deux systèmes. Dans cet exemple, vous devez vous assurer que le cluster Hortonworks peut communiquer avec votre instance du Studio Talend. Cela est nécessaire car Spark, même s'il s'exécute sur le cluster, doit faire référence aux pilotes Spark fournis avec Talend. De plus, si vous déployez un Job Spark dans un environnement de production, il sera exécuté depuis un serveur de Jobs Talend (nœud de périphérie, edge node). Vous devez également vous assurer que la communication est libre entre lui et le cluster.Pour plus d'informations concernant les ports nécessaires à chaque service, consultez la documentation Spark Security (uniquement en anglais) (en anglais).
-
Cliquez sur l'onglet Advanced settings et ajoutez un argument JVM indiquant la version de Hadoop. C'est la chaîne de caractères ajoutée en tant que valeur dans l'étape précédente.
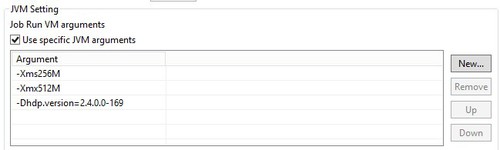
-
Cliquez sur l'onglet Basic Run, puis sur Run.
Lorsque l'exécution est terminée, un message s'ouvre, vous indiquant sa réussite.
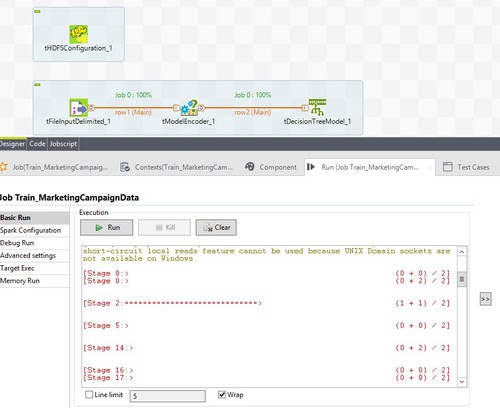
-
Naviguez jusqu'au répertoire HDFS, Ambari dans ce cas, afin de vérifier que le modèle a été créé et persiste dans HDFS.
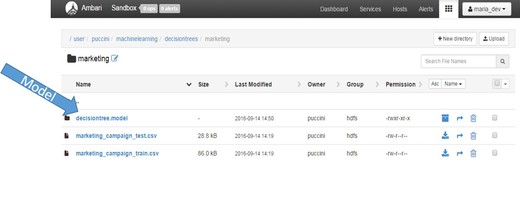
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !