
Configurer les composants
Procédure
-
Double-cliquez sur le composant nommé People pour afficher sa vue Basic settings.
 Note InformationsAvertissement :
Note InformationsAvertissement :La fonctionnalité de schéma dynamique est supportée uniquement en mode Built-In et requiert une ligne d'en-tête dans le fichier d'entrée.
-
Cliquez sur Edit schema pour définir le schéma de ce composant.
Dans ce scénario, le fichier d'entrée contient cinq colonnes : FirstName, LastName, HouseNo, Street, et City. Toutefois, comme vous allez profiter de l'option de schéma dynamique, vous n'aurez à définir qu'une seule colonne, ici nommée Dyna.Pour ce faire :
-
Dans la liste Type, choisissez Dynamic.

-
Dans la liste Type, choisissez Dynamic.
-
Double-cliquez sur le composant nommé Split_Column pour afficher sa vue Basic settings.
Ce composant vous servira à séparer la colonne du schéma d'entrée en deux colonnes : une pour le prénom et l'autre pour les informations concernant la famille. Pour cela :
-
Cliquez sur Edit schema pour ouvrir la boîte de dialogue Schema.

-
Cliquez sur Edit schema pour ouvrir la boîte de dialogue Schema.
-
Double-cliquez sur le composant nommé Deduplicate pour afficher sa vue Basic settings.

-
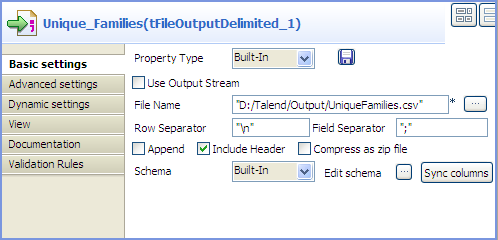
Dans la vue Basic settings du tFileOutputDelimited nommé Deduplicated_Families, définissez le chemin d'accès au fichier de sortie, cochez la case Include header et laissez les autres paramètres tels qu'ils sont.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !