
Générer le modèle de rapprochement
Procédure
-
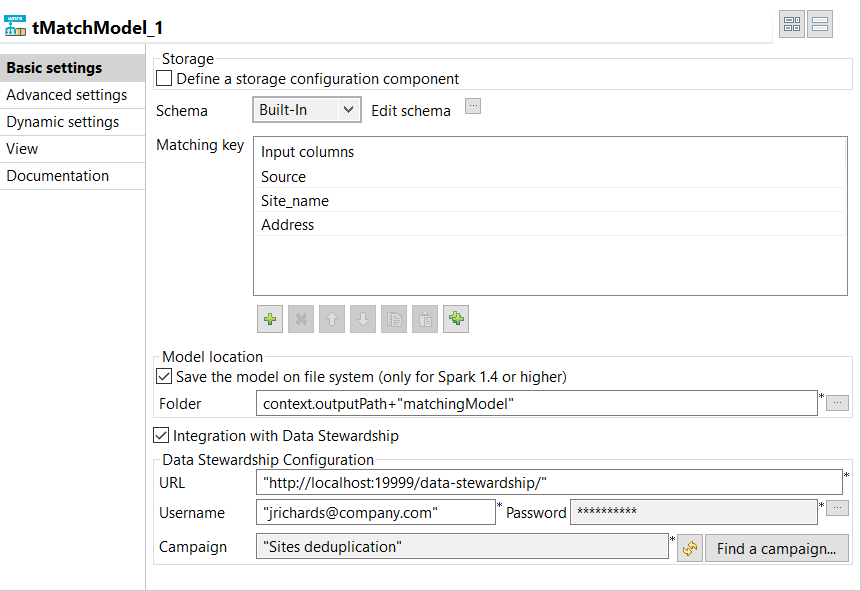
Double-cliquez sur le tMatchModel pour afficher sa vue Basic settings et définir ses propriétés.
Résultats
Vous pouvez utiliser ce modèle avec le composant tMatchPredict afin de libeller tous les doublons calculés par le tMatchPairing.
Pour plus d'informations, consultez Libeller des paires suspectes avec des libellés assignés.
Pour plus d'informations, consultez la documentation en ligne concernant les libellés des paires suspectes sur Talend Help Center (https://help.talend.com (uniquement en anglais)).
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !